Most interesting Google Patents for SEO in 2023
In this article I would like to contribute to archiving well-founded knowledge from Google patents.

Research Google patents is one of the smartest ways to understand modern search engines like Google. A pioneer in researching Google patents was the unforgettable Bill Slawski. He passed away in summer 2022. In his blog SEObythesea he published the insights from hundreds of Google patents and thus did an essential job for the entire SEO industry. He inspired me to research Google patents by myself and to write my own thoughts and theories from Google patents.
More about Google patents in my followings arcticles:
- The most interesting Google patents and scientific papers on E-E-A-T
- Most interesting Google Patents for semantic search
- Most interesting Google patents and research papers for ranking by Marc Najork
Are the systems and methods in the patents used by Google?
A patent application does not mean that the methods described there will find its way into practice in Google search. An indication of whether a methodology/technology is so interesting for Google that it could find its way into practice can be obtained by checking whether the patent is pending only in the US or other countries. The claim for a patent priority for other countries must be made 12 months after the first filing.
Regardless of whether a patent finds its way into practice, it makes sense to deal with Google patents, as you get an indication of the topics and challenges that product developers at Google are dealing with.
Below are summaries of the most interesting Google patents from 2023 and the last years. More about Google patents in my arcticle ” The most interesting Google patents and scientific papers on E-E-A-T“.
Enjoy!
Contents
- 1 Interesting Google patents of 2023
- 1.1 Embedding Based Retrieval for Image Search
- 1.2 Providing knowledge panels with search results
- 1.3 Predictive Query Completion and Predictive Search Results
- 1.4 Combining parameters of multiple search queries that share a line of inquiry
- 1.5 Multi source extraction and scoring of short query answers
- 1.6 Generative summaries for search results
- 1.7 Methods, systems, and media for presenting search results
- 1.8 Search result filters from resource content
- 1.9 Modifying search result ranking based on implicit user feedback
- 1.10 Evaluating an Interpretation for a Search Query
- 1.11 Query categorization based on image results
- 1.12 Embedding based retrieval for image search
- 1.13 Providing search results based on a compositional query
- 1.14 Mapping images to search queries
- 1.15 Privacy-sensitive training of user interaction prediction models
- 1.16 Combining content with a search result
- 1.17 Media item matching using search query analysis
- 1.18 Systems and methods for machine-learned prediction of semantic similarity between documents
- 1.19 Contextualizing knowledge panels
- 1.20 Content selection and presentation of electronic content
- 1.21 Systems and methods that match search queries to television subtitles
- 1.22 Television related searching
- 1.23 Generating and/or utilizing a machine learning model in response to a search request
- 1.24 Structured entity information page
- 1.25 Systems and methods for using document activity logs to train Machine-Learned models for determining document relevance
- 1.26 Query composition system
- 1.27 Query completions
- 1.28 Surfacing unique facts for entities
- 2 Most Interesting Google patents of the last years
Interesting Google patents of 2023
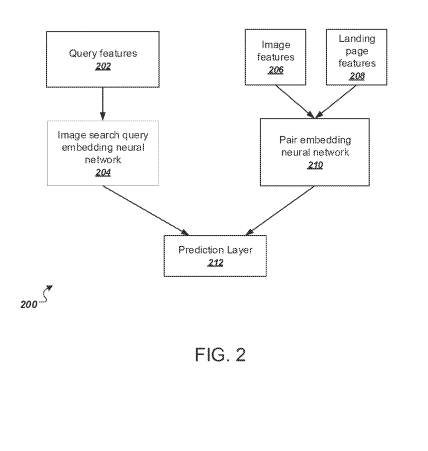
Embedding Based Retrieval for Image Search
This patent with the identifier US20230409653 is related to search engines and image search. This patent was published December 2023. It is published only for US, China, Europe and WIPO. This means that it is more likely to be used in practice. Inventors are Basu, Suddha Kalyan; Fan, Wei; Glasner, Daniel; Karanjkar, Sushrut Suresh; Strohmann, Thomas Richard; Verma, Shubhang; Pathak, Manas Ashok; Yin, Wenyuan; Tirumalareddy, Sundeep.
The patent describes a method where both image search queries and image-landing page pairs are processed through an embedding neural network model. This model creates embeddings in a shared space, allowing the system to identify the most relevant image search results based on the closeness of their embeddings to the query’s embedding. This method is more efficient and effective compared to traditional term-based retrieval systems, especially for long or obscure queries.

Process
- Receiving Image Search Query: The system starts by receiving an image search query from a user.
- Determining Pair Numeric Embedding: For each image-landing page pair, the system determines a numeric representation in an embedding space.
- Processing Query Features: The image search query embedding neural network processes the query’s features to generate a query numeric embedding in the same embedding space.
- Identifying Candidate Image Search Results: The system identifies a subset of image-landing page pairs whose pair numeric embeddings are closest to the query numeric embedding, marking them as first candidate image search results.

Factors
- Embedding Neural Network Model: Central to the process, it processes both the query and image-landing page pairs to generate embeddings in a shared space.
- Closeness in Embedding Space: The relevance of search results is determined by the closeness of their embeddings to the query embedding.
- Feature Embeddings: These model semantic relationships between features, improving the relevance of search results.
Implications for SEO
For SEO, this patent suggests a shift towards optimizing for semantic relevance rather than just keyword matching. It highlights the importance of ensuring that images and their associated landing pages are contextually relevant to the queries they aim to rank for. SEO strategies should focus more on the overall content and context of the landing page, as well as the semantic relationship between the content and the user queries.
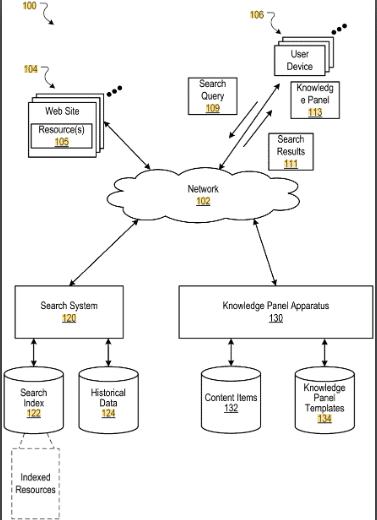
Providing knowledge panels with search results
This patent with the identifier US11836177B2 is related to search engines and semantic search. This patent was published December 2023. It is published only for US. Inventor is Jeromy William Henry.
The patent focuses on methods, systems, and apparatus for integrating knowledge panels into search results. These knowledge panels are designed to present information about factual entities referenced in a search query, enhancing the user’s search experience by providing quick access to relevant information.



Process
- Obtaining Search Results: The system first obtains search results responsive to a user’s query.
- Identifying Factual Entity: It identifies a factual entity (like a person, place, or event) referenced by the query.
- Content Identification for Knowledge Panel: The system identifies content for display in the knowledge panel, sourcing from multiple resources.
- Diverse Source Integration:
- The system is designed to aggregate content from multiple resources. This means that the knowledge panel doesn’t rely on a single source for its information.
- For instance, a knowledge panel about a historical landmark might include an image from one website and factual details from another.
- Quality and Relevance of Content:
- The selection of content is likely based on the quality and relevance of the information it provides. This implies a preference for authoritative and credible sources.
- The system may use algorithms to evaluate the trustworthiness and accuracy of the content from different sources.
- User Search Behavior and Interaction:
- The patent suggests that the choice of content could be influenced by user search behavior. This means that popular or frequently accessed information about an entity might be prioritized.
- User interactions with the knowledge panel could further refine the content selection, tailoring it to what users find most useful or engaging.
- Entity-Specific Content Selection:
- The system tailors the content based on the type of entity. For example, for a famous person, the panel might include photos, a brief biography, and notable facts.
- This entity-specific approach ensures that the knowledge panel is relevant and provides a comprehensive overview of the subject.
- Dynamic Content Adaptation:
- The knowledge panels are not static; they can adapt and change based on new information or changing user interests.
- This dynamic nature means that the choice of resources can evolve over time, maintaining the relevance and accuracy of the information presented.
- Diverse Source Integration:
- Presentation: The identified search results and the knowledge panel are presented on a search results page, with the knowledge panel alongside the search results.

Factors
- Content Variety: The content in a knowledge panel includes items like images, titles, facts, etc., obtained from diverse resources.
- User Interaction: The knowledge panel may include interactive elements, allowing for expanded content based on user interactions.
- Entity Types: The system can handle multiple entity types, like persons or places, and tailor the knowledge panel accordingly.
- Template-Based Display: Knowledge panels are generated using templates based on the type of entity.
Implications for SEO
- Emphasis on Entity-Based Search: SEO strategies should focus on optimizing content for specific entities (people, places, events) to be featured in knowledge panels.
- Rich Content Diversity: Diverse and rich content types (images, facts, interactive elements) become crucial for visibility in knowledge panels.
- Quality and Authority of Sources: High-quality, authoritative sources are likely favored for content in knowledge panels, emphasizing the need for credible and well-referenced content.
- Building Authority: Websites should aim to become authoritative sources in their niche, increasing the likelihood of their content being featured in knowledge panels.
- User Engagement: Interactive elements in knowledge panels suggest a shift towards more engaging content that can prompt user interaction.
- Content Diversity and Richness: SEO strategies should focus on creating diverse and rich content that could be sourced for knowledge panels.
- Monitoring User Behavior: Understanding what users frequently search for and engage with can help in tailoring content to be more relevant for knowledge panels.
Predictive Query Completion and Predictive Search Results
This patent with the identifier US20230394072A1 is related to search engines and search query processing. This patent was published December 2023. It is published for US, Europe, Germany, Australia and China. This means that it is more likely to be used in practice. Inventors are Othar Hansson, David Black, Wiley, Jon M., Manas Tungare, Ziga Mahkovec, Benjamin J. Mcmahan, Benedict A. Gomes, Jonathan Effrat, Johanna R. Wright, Marcin K. Wichary.
The patent focuses on enhancing search query suggestions and the delivery of search results. It introduces a system where search results are provided based on prediction criteria, independent of user selection of query suggestions or completion of a query. The patent describes a method to enhance user experience in search engines by providing search results based on predictive criteria, without overwhelming the user with unnecessary data. It aims to reduce bandwidth usage and improve the relevance of search results.

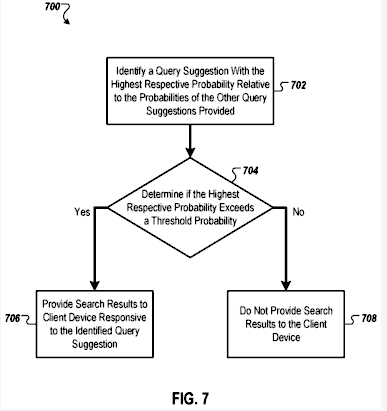
Process:
- Receiving Query Suggestions: The system receives query suggestion requests from a client device as the user inputs a query.
- Providing Query Suggestions: In response to each request, query suggestions are provided.
- Determining Prediction Criterion: The system determines if a prediction criterion is met. This criterion is independent of user selection or query completion.
- Providing Search Results: If the prediction criterion is met, search results corresponding to one of the query suggestions are provided to the client device.
- Non-Provision in Absence of Criterion: If the prediction criterion is not met, search results are not provided.


Factors:
- Prediction Criterion: This could be a probability threshold, a timeout, or a signal of likely user interest.
- User Interface Techniques: Techniques like “fade-in” and “fade-out” are used for smooth transitions in displaying search results.
- Reordering of Query Suggestions: Suggestions can be re-ordered into stemmed groups to match typing inputs.
Implications for SEO:
This patent suggests a shift towards more predictive and user-intent-focused search results. For SEO, this means:
- Greater Focus on User Intent: Understanding and aligning content with potential user intent becomes crucial.
- Importance of Query Suggestions: Optimizing for query suggestions and probable search terms gains significance.
- Content Relevance: Ensuring content relevance and quality is more important, as search results are more tailored to user behavior and less to explicit queries.
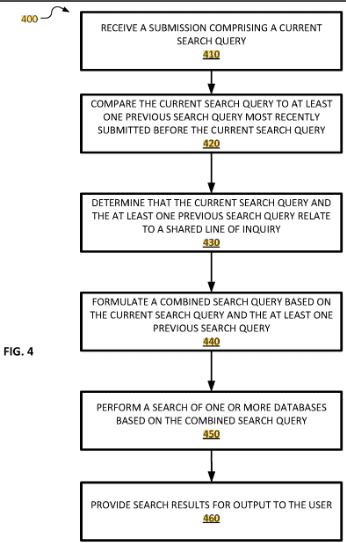
This patent with the identifier US11762848B2 is related to search engines and search query processing. This patent was published September 19, 2023. It is published for US and China. Inventors are Matthew Sharifi, Victor Carbune.
The patent focuses on improving search query processing. It presents a method for generating a combined search query based on the parameters of a current search query and one or more previous queries from the same user, provided that these queries have a common query line.
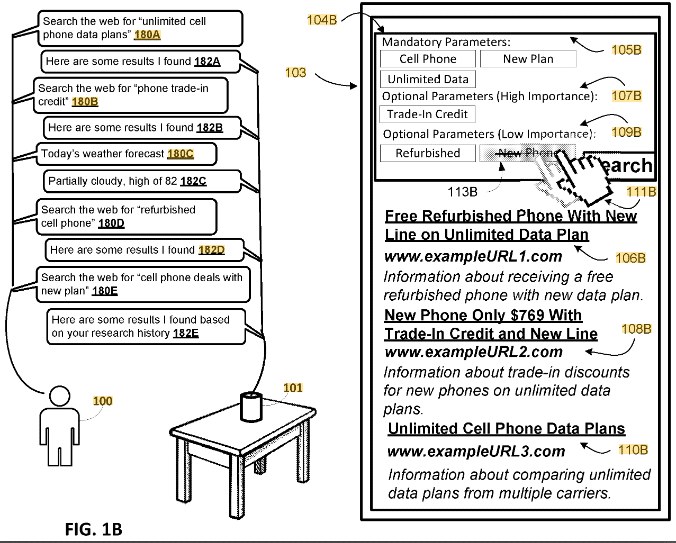
The patent describes a method for optimizing the online search experience by intelligently combining multiple related search queries into a single, more effective search query. This approach utilizes semantic analysis and user interaction, potentially reducing redundancy in search results and increasing the relevance of retrieved information.
The patent describes a method to improve online search efficiency by intelligently combining parameters from multiple related search queries. This approach reduces redundancy in search results and adapts to the evolving nature of a user’s search intent.
Process
- Semantic Similarity Analysis: The system compares new and previous queries for semantic similarity. If they are semantically related, their parameters are combined into a new query.
- Linking Grammar and Heuristics: Utilizes grammatical structures and heuristics to identify related queries. For example, a user changing a query from “Bluetooth earbuds” to “true wireless earbuds” triggers a combined query including both sets of parameters.
- Stateful Research Mode: Users may be prompted to enter a mode where their search queries are automatically combined based on shared lines of inquiry.
- Interactive GUI: An interactive interface allows users to modify search parameters, including adding or excluding certain terms from the combined query.
Factors
- Latent Space Analysis: Distance in latent space between query embeddings is used to assess semantic similarity.
- User Interaction: The system learns from user interactions with search results to refine the similarity function and combined query formulation.
- Coordinated Ecosystem of Computing Devices: The system can be implemented across various devices, enhancing user experience in multi-device environments.
Implications for SEO
- Enhanced User Intent Understanding: SEO strategies must adapt to a more nuanced understanding of user intent, as Google’s search algorithms become better at interpreting and linking related queries.
- Long-Tail Keyword Optimization: The importance of long-tail keywords may increase, as combined queries can create more specific, long-tail search patterns.
- Content Relevance: Content must be more closely aligned with potential search query combinations to remain relevant in search results.
- Semantic Search Optimization: Emphasis on semantic search optimization, ensuring content is relevant to a wider array of semantically linked queries.
Essentially, this patent points to a significant shift towards a more nuanced, context-aware search process that could reshape SEO strategies with a focus on semantic relevance and user intent.
This patent indicates a shift towards more intelligent, context-aware search processes, necessitating a more sophisticated approach to SEO that accounts for the dynamic nature of user search behavior.
Multi source extraction and scoring of short query answers
This patent with the identifier US20230342411A1 is related to search engines. This patent was published October 26, 2023. It is published for US, WIPO. Europe, South Corea, China. This means that it is more likely to be used in practice. Inventors are Preyas Dalsukhbhai Popat, Gaurav Bhaskar Gite, John Blitzer, Jayant Madhavan, Aliaksei Severyn.

The patent aims to improve the quality of short answers provided by search engines. The patent focuses on generating short answers for search queries. It involves a training operation on a corpus of training data to train a score prediction engine. This engine is used to select and score passages from search results, determining the best short answer to display in search engine callouts.
The patent’s focus on generating short answers for search queries is closely related to what we know as Featured Snippets in Google’s search results. Featured Snippets are selected search results that are featured on top of Google’s organic results in a box and are designed to answer the user’s question directly. The patent suggests a more sophisticated approach to selecting these snippets, ensuring they are not only relevant but also accurate.

Process
- Receiving Query Data: The method starts with receiving a search query input by a user.
- Generating Search Results: A plurality of search results are generated based on the query, each having a passage related to the query.
- Selecting Passages: A set of passages is selected, including a candidate passage from a top-ranked search result and context passages from other results.
- Scoring Candidate Passage: The candidate passage is scored using context passages to produce an accuracy score.
- Displaying Short Answer: Based on the accuracy score, the candidate passage is provided for display as a short answer in the search results.

Factors
- Accuracy Score: Determined by the accuracy score prediction engine, it predicts the accuracy of a passage from a top-ranked search result based on consensus with other passages.
- The candidate passage is evaluated in the context of the other selected passages.
- The idea is to assess the candidate passage’s accuracy by comparing it with information provided in the context passages. This comparison seeks to establish a consensus or agreement among the different sources.
- An ‘accuracy score prediction engine’ is employed for this scoring process. This engine is trained using a corpus of training data, which includes passages from search engine results that have been manually scored by raters. These raters score based on how well the passages agree or form a consensus with context passages from other search results.
- The candidate passage is assigned an accuracy score based on this evaluation.
- Whether or not the candidate passage is displayed as a short answer in the search results depends on whether its accuracy score meets or exceeds a certain threshold. If the score is above the threshold, it is deemed accurate enough to be displayed.
- The accuracy score prediction engine is likely designed to learn and improve over time, adapting to new data and possibly user feedback, to enhance its scoring accuracy.
- Training Data: The engine is trained using passages from search engine results, manually scored by raters based on consensus with context passages.
Implications for Content and SEO
- Content Quality and Consensus: The accuracy score determination suggests that content which is in consensus with other reputable sources on the same topic is more likely to be featured as a short answer.
- Importance of Comprehensive Information: Providing detailed, well-researched content that aligns with information from other authoritative sources could increase the likelihood of being selected for short answers.
- Adaptation to AI and Machine Learning: SEO strategies should consider how AI-driven systems evaluate content, focusing on factual accuracy and the broader context of information.
- Focus on Accurate and Relevant Content: SEO strategies should prioritize content accuracy and relevance, as the patent emphasizes scoring based on these factors.
- Importance of Contextual Information: Providing comprehensive information and context in content could increase its chances of being selected as a top passage.
- Adaptation to AI-Driven Search Results: SEO professionals need to understand and adapt to AI-driven mechanisms in search engines, focusing on how algorithms evaluate and score content.
- Quality Over Quantity: The patent suggests a shift towards quality content, as search engines aim to provide the most accurate short answers.
Generative summaries for search results
This patent with the identifier US11769017B1 is related to search engines and SGE. This patent was published September 26, 2023. It is only published for US. Inventors are Matthew K. Gray, John Blitzer, Corinn Herrick, Srinivasan Venkatachary, Jayant Madhavan, Sam Oates, Phiroze Parakh, Aditya Shah, Mahsan Rofouei, Ibrahim Badr. Expiration Date is March 20, 2043.

The paten focuses on improving the accuracy and relevance of natural language (NL) based summaries generated in response to search queries. It specifically addresses the use of a large language model (LLM) to process additional content beyond the query itself, aiming to reduce inaccuracies and ensure the summaries are neither over-specified nor under-specified.
It focuses on processing additional relevant content alongside the query to create more accurate, contextually appropriate, and user-specific summaries. This approach addresses common issues like inaccuracies and generic responses in current search technologies.

Process
- Utilizing LLMs: The LLM processes both the query content and additional related content to generate NL based summaries.
- Addressing Inaccuracies: By processing additional content, the system aims to mitigate inaccuracies that might arise from outdated or insufficient training data.
- Adjusting to Query Submissions: The system processes different additional content for different submissions of a given query, leading to varied and more personalized responses.

- Incorporating User Interaction: The system can revise the NL based summary based on user interactions with search results, making the information more relevant and up-to-date.
- User Familiarity Consideration: The system can adjust the content of the summary based on the user’s familiarity with the subject matter, determined through user profiles or previous interactions.

Factors
- Query Content: The actual content of the user’s search query.
- Additional Content: Includes content from query-responsive documents, related-query-responsive documents, and recent-search-responsive documents.
- User Interaction: The user’s interaction with search results can influence the content of the generated summary.
- User Familiarity: The system considers the user’s existing knowledge or familiarity with the subject matter.
Methods, systems, and media for presenting search results
This patent with the identifier US11829373B2 is related to search engines. This patent was filed 02/20/2015 and published in November 2023. Inventors are Eileen Margaret Peters Long, Jonathan Frankle, Will Chambers, Jia Wu, Charles Thomas Curry, Matthias Heiler, Ruben Sipos, Christopher Kenneth Haulk, Angela Yu-yun Yeung, Ingrid Karin Von Glehn.
The patent focuses on improving the way search results are presented, particularly in filtering and categorizing content based on its suitability for different audiences. It involves receiving search queries, determining content rating scores, and presenting results based on these scores. The system aims to filter and categorize content effectively, ensuring appropriate content delivery to various user demographics.
Process
- Receiving Search Queries: The system receives text corresponding to a search query entered on a user device.
- Determining Content Rating Score: It determines whether a content rating score associated with the search query is below a predetermined threshold. This score is calculated by identifying a set of search results retrieved using the query, where each result is associated with one of several content rating classes.
- Calculating Proportion: The content rating score represents the proportion of search results associated with at least one of the content rating classes.
- Presenting Search Results: If the content rating score is below the threshold, a second set of search results is identified and presented based on the search query.

Factors
- Content Rating Classes: These may include classes suitable for all ages and classes suitable for adults.
- Weight Application: Weights can be applied to each search result based on relevance to the query.
- Adjustment of Results: The second set of search results can be a subset of the first, adjusted based on content rating classes.
Search result filters from resource content
This patent with the identifier US11797626B2 is related to search engines and search query processing and SERP serving. This patent was filed in June 2022 and published in October 2023. It was published for US, China, Europe, Russia. This means that it is more likely to be used in practice. Inventors are Ian MacGillivray, Kaylin Spitz, Selena Sunling Yang, Varun Jasjit, Singh Emma S. Persky,Yonatan Erez.
The patent describes a system for generating dynamic search query filters based on the content of resources (like web pages) that are responsive to a user’s search query. This system aims to refine search results and enhance user experience by providing more relevant and diverse search options.

Concept
- Data Processing: The system processes a user’s search query to identify relevant resources.
- Function: The system processes a user’s search query to identify relevant resources (like web pages, documents, etc.).
- Mechanism: When a search query is input, the system searches its indexed resources to find those that are most relevant to the query.
- Example: If a user searches for “best smartphones 2023”, the system will process this query to identify and select web pages, articles, and reviews about the latest smartphones.
- Keyword Extraction: From these resources, it extracts keywords and generates a set of candidate query filters.
- Function: Extracting keywords from the content of resources identified as relevant to the search query.
- Process: After identifying relevant resources, the system analyzes their content to extract a set of keywords. These keywords represent the main topics or themes of the resources.
- Example: From articles about smartphones, keywords like “battery life”, “camera quality”, “5G support” might be extracted, representing key aspects users are interested in.
- Filter Selection: These candidate filters are then refined based on diversity criteria to ensure they represent different aspects of the search results.
- Function: Refining the extracted keywords to create a set of diverse and relevant query filters.
- Criteria for Selection:
- Diversity Threshold: Ensures each filter represents a different aspect of the search results.
- Difference Threshold: Filters should lead to substantially different sets of search results.
- Process: The system trims the set of candidate query filters using these criteria, ensuring a diverse range of filters.
- Example: From the keywords extracted about smartphones, filters like “Best Camera Phones”, “5G Smartphones”, “Long Battery Life Phones” might be created, each leading to a different subset of search results.
- User Interaction: The final set of query filters is displayed to the user alongside the search results, allowing for more targeted searching.
- Function: Presenting the generated filters to the user alongside the search results.
- User Experience: Users can refine their search results by selecting these filters, leading to a more targeted set of results.
- Dynamic Interaction: Filters change dynamically based on the search query and the content of the resources currently available.
- Example: In the smartphone search scenario, a user might initially see a broad set of results. By selecting the “Best Camera Phones” filter, the results would then focus specifically on phones renowned for their camera quality.

Key Insights
- Dynamic Filter Generation: Filters are not hardcoded but are dynamically created based on the content of search results, making them more relevant and up-to-date.
“The keywords are processed according to candidate selection criteria, and a set of candidate query filters are determined.”
- Diversity in Filters: The system ensures diversity among the filters, so they represent different facets of the search results.
“The set of candidate query filters is trimmed using diversity criteria, ensuring that remaining candidate query filters have a reasonable degree of diversity.”
- Application Across Various Domains: This technology is not limited to general web searches but can be applied to specific domains like restaurant reviews or product searches.
“The features can be applied to any system or application that searches a data store.”
- Enhanced User Experience: By providing relevant and diverse filters, the system aims to make the search process more efficient and user-friendly.
“Learned filters from item reviews and descriptions enable a search engine system to provide search results in specific domains which vary not just with the categorical query but also with the results available at the time of the search.”

The patent outlines a method for enhancing search engine functionality by dynamically generating query filters based on the content of resources relevant to a user’s search query. This approach aims to provide a more tailored and efficient search experience by offering diverse and relevant filtering options, adaptable to various search domains.
Implications for SEO
Understanding these components is crucial for SEO professionals as it underscores the importance of creating diverse, rich, and relevant content that aligns with potential search filters. By anticipating and aligning with these dynamic filters, websites can better position themselves in search results, catering to specific user interests and queries.
- Focus on Diverse and Relevant Content: SEO strategies should emphasize creating content that covers a wide range of relevant topics within a domain, as this could influence the dynamic filters generated by the search engine.
- Keyword Optimization: Understanding the most relevant and diverse keywords within a domain becomes crucial, as these are likely to influence the generation of search filters.
- Adaptability to User Intent: SEO efforts should be more aligned with understanding and addressing user intent, as the search engine is focusing on dynamically catering to these intents through filters.
- Monitoring Emerging Trends: Staying updated with emerging keywords and trends in a domain is vital, as these could quickly become part of the dynamic filters in search results.
- Enhanced User Engagement: Websites should aim to provide comprehensive and diverse information to engage users better, as this could influence their visibility in filtered search results.
Modifying search result ranking based on implicit user feedback
This patent with the identifier US11816114B1 is related to search engines and especially ranking. This patent was filed in November 2021 and published in November 2023. It was published only for US. Inventors are Kim, Hyung-jin (Sunnyvale, CA, US), Tong, Simon (Mountain View, CA, US), Shazeer, Noam M. (Palo Alto, CA, US), Michelangelo (Zurich, CH). The patent is based on an older patent US10229166B1.
The core of this patent revolves around modifying search result ranking based on implicit user feedback. It focuses on a system that determines the relevance of a document in the context of a search query, primarily using user interaction data.
- Document Relevance Determination: The system determines the relevance of a document based on the duration of views it receives following a search query. Longer views are considered indicative of higher relevance.
- Ranking Based on User Interaction: The patent describes a method where the ranking of a document in search results is influenced by the ratio of longer to shorter views. This approach suggests that user engagement, particularly the time spent on a page, plays a significant role in determining its relevance and ranking.

Key Insights
- Linking and Relevance: The patent mentions the concept similar to Google’s PageRank system, where the relevance of a document increases if it is linked by other relevant documents. This highlights the importance of backlinks from quality sources.
- User Engagement Metrics: The system emphasizes user engagement metrics, particularly the length of time users spend viewing a document. Longer views are weighted more heavily, suggesting that content that engages users for longer periods is likely to be ranked higher.Here are the key user engagement metrics mentioned in the patent:
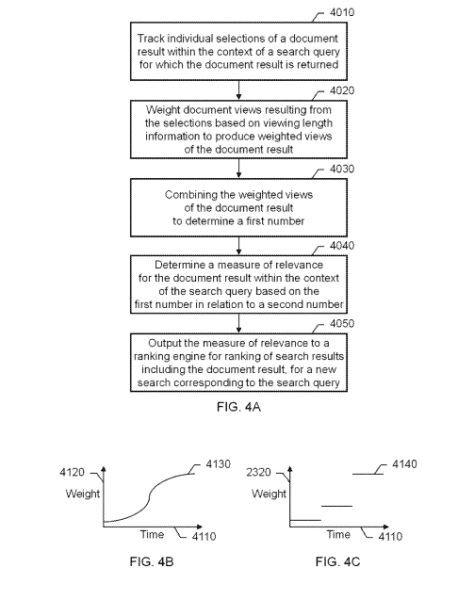
- Viewing Time Categories: The system classifies individual selections of the document result into viewing time categories. This classification is based on the duration for which users view the document after selecting it from search results.
- Weight Assignment Based on Viewing Time: Weights are assigned to individual selections based on the results of the classification into viewing time categories. This implies that different durations of views are valued differently, with longer views likely receiving higher weights.
- Viewing Length Differentiators: The system identifies one or more viewing length differentiators, such as query category and user type. This suggests that the context of the search and the characteristics of the user are considered when evaluating the significance of the viewing time.
- Weighting Document Views: Document views are weighted based on the viewing length information in conjunction with the viewing length differentiators. This means that the system takes into account both the duration of the view and the context in which the view occurred.
- Tracking User Selections and Viewing Time: The system tracks individual user selections of the results and the amount of time spent viewing the selected document result. This tracking can be implemented through various methods, such as embedded JavaScript code, proxy systems, or pre-installed software at the client.
- Result Selection Logs: The recorded information about user interactions is stored in result selection logs. These logs include data such as the query, the document selected, the time spent on the document, the language used by the user, and the user’s likely location.
- Ratio of Longer to Shorter Views: The patent describes a method of determining a measure of relevance for a document based on a ratio between the number of longer views and the number of shorter views. This ratio is then used to influence the ranking of the document in search results.
- Audio Presentations and Speech Input: The patent also considers audio presentations and speech input in client devices, indicating a focus on multimedia content and voice search optimization.
The patent outlines a system for ranking search results based on user interactions, particularly the length of time users spend on a page. It suggests that both the quality of backlinks and user engagement metrics are crucial factors in determining the relevance and ranking of a document in search results.
Implications for SEO
- Content Quality and Engagement: SEO strategies should focus on creating high-quality, engaging content that keeps users on the page longer.
- Backlink Strategy: Acquiring backlinks from relevant and authoritative sources remains crucial, as indicated by the patent’s emphasis on the relevance of linking documents.
- Multimedia and Voice Search Optimization: With the inclusion of audio presentations and speech input, optimizing for multimedia content and voice search becomes increasingly important.
For SEO practitioners, this means adapting strategies to focus more on user experience, content quality, and the evolving landscape of voice and multimedia search. For SEO, this means that not only is the click-through rate important, but also how long and in what context users engage with the content after clicking through. This reinforces the importance of creating content that is not only relevant and useful but also engaging enough to retain users’ attention for longer periods.
Evaluating an Interpretation for a Search Query
This patent with the identifier US20230334045A1 is related to search engines and especially search query processing. This patent was first published in October 2023. It was published for US, China, South Corea, Europe and WIPO. This means that it is more likely to be used in practice. Inventors are Jeffrey Bergman, Pavlo Poliakov, Matthew William Dawson, Kevin Rothi, Chifeng Wen.
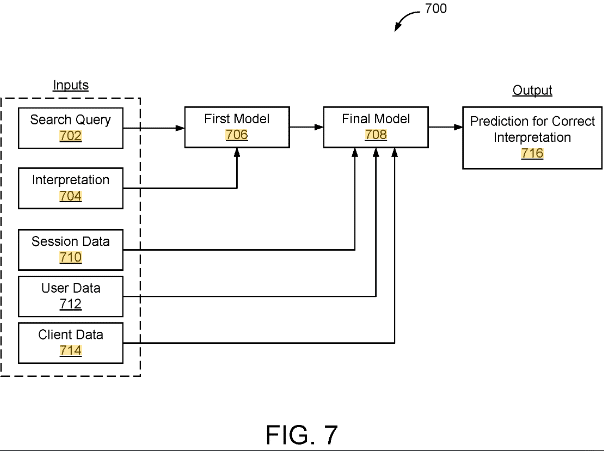
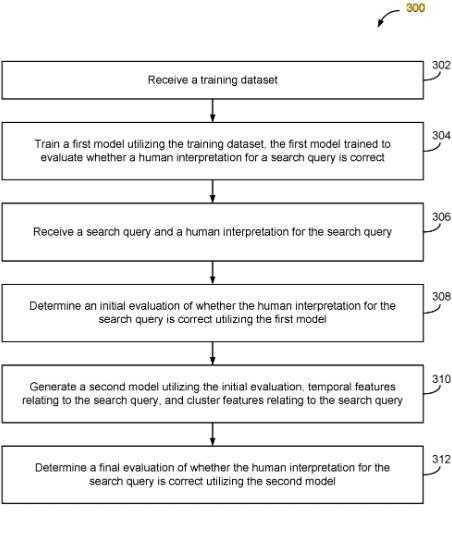
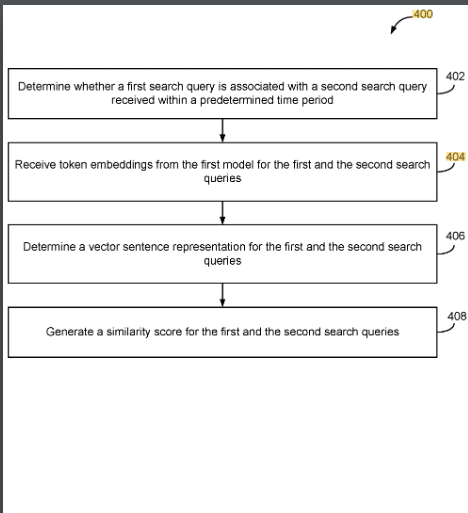
The patent describes a method and system for evaluating the accuracy of a human interpretation of a search query. This process involves two main models:
- First Model: Trained using a dataset comprising past search queries, their human interpretations, and human-evaluated labels indicating the correctness of these interpretations. This model initially assesses whether a human interpretation of a search query is correct.
- Second Model: Developed using the initial evaluation from the first model, along with temporal and cluster features related to the search query. This model provides a final evaluation of the correctness of the human interpretation.
The Google patent discusses the concept of grouping or clustering search queries, which is a significant part of its approach to evaluating search query interpretations. Here are more details about the grouping factors or criteria of queries as outlined in the patent:
- Temporal Features:
- The patent emphasizes the use of temporal features in the evaluation process. This suggests that the time-related aspects of a search query, such as the time of day, season, or specific events occurring around the time the query was made, could be crucial in grouping queries.
- Temporal proximity of queries might also be considered, where queries made close in time are potentially grouped together, under the assumption that they might be related or influenced by similar external factors.
- Cluster Features:
- The system generates clusters of search queries based on similarities between them. This implies that queries with similar themes, topics, or keywords are likely to be grouped together.
- The clustering could be dynamic, updating as new search queries are received, ensuring that the grouping remains relevant and reflective of current search trends or patterns.
- Search Query Refinements:
- The patent describes a process where the system determines if a subsequent search query is a refinement of a previous one. This could be a factor in grouping queries, where initial queries and their refinements are grouped together for a more comprehensive understanding of the user’s intent.
- A refinement is seen as a weighted indication of an incorrect human interpretation of the initial query, suggesting that these sets of queries are crucial for understanding and improving query interpretation accuracy.
- Vector Sentence Representations:
- The system involves determining vector sentence representations for search queries by averaging token embeddings. This technique suggests that semantic similarities between queries (how closely the meaning of one query relates to another) play a role in grouping.
- The use of token embeddings and vector representations indicates an advanced, nuanced approach to understanding the semantic and contextual relationships between different queries.
- Distance Algorithms:
- The patent mentions the use of distance algorithms, such as Euclidean distance or cosine similarity algorithms, to parse search queries. These algorithms help in determining the similarity or ‘distance’ between different queries, contributing to how they are grouped.
- Such algorithms can quantify the similarity between queries in a multi-dimensional space, where each dimension can represent a different feature or aspect of the queries.
The patent does take into account the concept of search intent, although it may not explicitly use the term “search intent.” The patent’s focus on evaluating the accuracy of human interpretations of search queries inherently involves understanding what the user is seeking or intending to find through their query. Here’s how the concept of search intent is implicitly addressed in the patent:
- Human Interpretation of Search Queries:
- The system evaluates the correctness of human interpretations of search queries. This process necessitates an understanding of what the user meant or intended to find with their query, which is at the core of search intent.
- Search Query Refinements:
- The patent discusses identifying if a subsequent search query is a refinement of a previous one. This aspect is closely tied to search intent, as refinements often occur when the initial search results do not fully meet the user’s intent, prompting them to adjust their query for more accurate results.
- Temporal and Cluster Features:
- By considering temporal and cluster features in evaluating search queries, the system indirectly addresses the context and nuance of search intent. For instance, queries made at specific times or within certain thematic clusters can provide insights into what users are intending to find.
- Training Dataset with Human-Evaluated Labels:
- The training dataset includes human interpretations and evaluated labels for past search queries. This aspect suggests that the system learns from past instances where human judgment was applied to discern the intent behind a query.
- Vector Sentence Representations and Distance Algorithms:
- The use of vector sentence representations and distance algorithms to parse and group queries also touches on search intent. These techniques help in understanding the semantic meaning and nuances of queries, which are essential for discerning user intent.
In summary this Google patent presents a sophisticated method for evaluating search query interpretations, with an underlying focus on understanding and catering to user search intent. This approach, which leverages machine learning, temporal and cluster analysis, and advanced computational techniques, has significant implications for SEO practices, emphasizing the need to align with how search engines interpret and cater to user intent.
Interesting in this patent is also the mention of BERT. It can therefore be assumed that this methodology can also play a role in BERT.

Implications for SEO
- Emphasis on Accurate Query Interpretation: SEO strategies should focus more on aligning content with the probable interpretations of search queries by users.
- Importance of Context and Temporality: Content should be optimized considering the temporal context and potential clustering of topics or keywords.
- Adaptation to Search Refinements: Websites should be optimized to cater to refined searches, as these might indicate initial misinterpretations by search engines.
- Leveraging Natural Language Processing: Incorporating NLP strategies in content creation might become more crucial to align with how search engines interpret queries.
Query categorization based on image results
This patent with the identifier US11782970B2 is related to search engines and especially image search and search query processing. This patent was first published in July 2022 by Google and republished in October 2023. It was published only for US. Inventors are Anna Majkowska, Cristian Tapus. Expiration date is 2029.
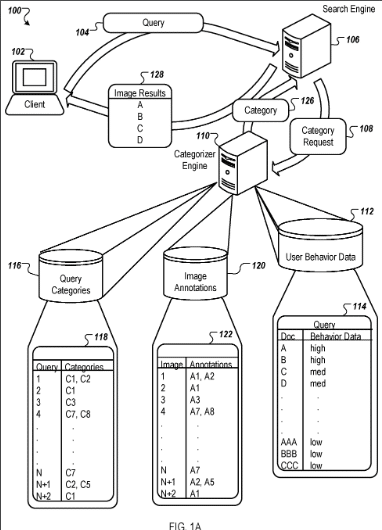
The patent is focused on a method for categorizing search queries based on the analysis of image search results. It involves receiving images from image search results, each associated with user behavior data, and then annotating these images based on content analysis.
The concept behind this patent is to improve the relevance, quality, and diversity of image search results by using user interaction data to derive categories for queries. This categorization can then inform future search results, making them more accurate and tailored to user intent.
Key Insights:
- User Behavior Data Utilization: The patent describes a method that includes obtaining images from image results responsive to a query, where the images are associated with scores and user behavior data indicating user interaction with the images when they were presented as search results.

- Image Annotation and Categorization: Selected images that meet a behavior data threshold are annotated based on content analysis. These annotations are then used to categorize the query, which can be stored for future use to improve search result relevance.
- Query and Image Association: The method can modify future image results based on the categories associated with previous queries, enhancing the search experience by, for example, increasing the scores of images that contain a single face for a single person query or diverse images for a diverse query.
- Association and Ranking Modification: The method involves determining an association between a first query and a second query. Once this association is established, the search engine modifies the ranking for a second set of image results based on categories associated with the first set of image results. This modification includes increasing the ranking of particular image results in the second set if they are associated with the categories of the first query.
Quote: “modifying, via the search engine, a ranking for the second set of image results based on the one or more categories associated with the first set of image results, wherein modifying the ranking comprises: determining one or more particular image results of the second set of image results are associated with the one or more categories; and increasing the ranking of the one or more particular image results based on the one or more particular image results having an association with the one or more categories of the first query.”

- Image Analysis and Category Generation: The system uses computer vision techniques to analyze images and generate categories based on visual features identified in the images. This categorization process is performed by a categorizer engine that processes a subset of the images to determine the categories associated with image results.
Quote: “determining, by processing at least a subset of the plurality of images with a categorizer engine, one or more categories associated with the first set of image results, wherein at least one of the categories specifies a presence of a particular visual feature in one or more images of the plurality of images.”
- Query Transformation: The method includes determining if a second query can be transformed into an alternative form that is the same or similar to the first query, which can influence the ranking of the image results.
Quote: “determining that the second query can be transformed into an alternative form that is same or similar to the first query.”
- Relevance Determination: The ranking for the second set of image results is also based on a determined relevance associated with each image result. This suggests that the system takes into account how relevant each image is to the query when adjusting the rankings.
Quote: “determining the ranking for the second set of image results based on a determined relevance associated with each image result.”
- User Interaction and Query Suggestions: The system utilizes user interaction with image search results to derive categories for queries. These categories can improve the relevance, quality, and diversity of image search results and can be used to provide automated query suggestions.
Quote: “User interaction with image search results can be used to derive categories for queries. Query categories can, in turn, improve the relevance, quality and diversity of image search results.”

Categorization process
The categorization process involves several steps that are executed by a computing system comprising one or more processors. Here is a detailed breakdown of the process:
- Receiving a Query: The system receives a first query from a user, which comprises a set of text characters.
- Obtaining Image Results: By processing the first query with a search engine, the system obtains a plurality of images associated with a first set of image results that are responsive to the first query.
- Determining Categories with a Categorizer Engine: The system processes at least a subset of the obtained images with a categorizer engine to determine one or more categories associated with the first set of image results. These categories specify the presence of particular visual features in one or more images of the plurality.
- Generating Associations: An association between the first query and the one or more determined categories is generated based at least in part on the first set of image results.
- Receiving a Second Query: The system receives a second query, which also comprises a set of text characters.
- Obtaining Second Set of Image Results: By processing the second query with the search engine, a second set of image results is obtained, which are responsive to the second query.
- Determining Query Associations: The system determines if the second query is associated with the first query.
- Modifying Rankings Based on Categories: The search engine modifies the ranking for the second set of image results based on the one or more categories associated with the first set of image results. This involves:
- Determining which particular image results of the second set are associated with the one or more categories.
- Increasing the ranking of those particular image results based on their association with the categories of the first query.
- Analyzing Images: The system analyzes the images using computer vision techniques to assist in the categorization process.
- Determining Faces and Similarities: It determines how many faces are in each of the images and whether a subset of images are similar based on a plurality of fingerprints (unique identifiers for images).
The patent also mentions that the system can associate images from image results with a plurality of annotations based on the analysis of the images’ content. This suggests that the categorization process is not only about grouping images into categories but also about understanding and annotating the content within the images to improve the relevance and quality of search results.
Implications for SEO
The patent suggests that Google may use image analysis and user interaction data to categorize queries and adjust search rankings accordingly.
For SEO, this implies that:
- Image Optimization: SEO strategies should ensure that images are well-optimized and categorized correctly to improve their chances of ranking higher in associated query results.
- User Engagement: User behavior with image results can influence query categorization, so SEO efforts should also focus on improving user engagement with images.
- Semantic Similarity: The transformation of queries into similar forms indicates that semantic understanding of content is crucial, and SEO should consider the intent and contextual relevance of content, not just keyword matching.
Embedding based retrieval for image search
This patent with the identifier US11782998B2 is related to search engines and especially image search. This patent was first published in January 2022 by Google and republished in October 2023. It was published for US, Europe, China and WIPO. This means that it is more likely to be used in practice. Inventors are Suddha Kalyan, BasuWei Fan,Daniel Glasner,Sushrut Suresh Karanjkar,Thomas Richard Strohmann, Shubhang Verma Manas, Ashok Pathak, Wenyuan YinSundeep, Tirumalareddy.
The patent is focused on a method and system for improving image search results using an embedding neural network model. This model processes image search queries and the associated image-landing page pairs to generate numeric embeddings in a shared embedding space. The core of this technology is to determine the closeness of these embeddings to the query’s numeric embedding to identify the most relevant image search results.
Core concept:
The core innovation of the patent is an embedding-based retrieval system for image searches that uses a trained neural network model to process image search queries and their associated image-landing page pairs.
The concept involves receiving an image search query and determining a numeric embedding for each image-landing page pair. These embeddings are numeric representations in a shared embedding space. The image search query is also processed through an embedding neural network to generate a corresponding numeric embedding. The system then identifies the closest pair numeric embeddings to the query numeric embedding as the most relevant search results.

“In one aspect, an image search query is received. A respective pair numeric embedding for each of a plurality of image-landing page pairs is determined… An image search query embedding neural network processes features of the image search query and generates a query numeric embedding.”

Key Insights:
- The embedding neural network model can handle features of the image search query, the landing page, and the image itself, providing a more semantically rich representation of the search results.
“Unlike conventional methods to retrieve resources, the embedding neural network model receives a single input that includes features of the image search query, landing page and the image identified by a given image search result and generates an embedding representation of the image search result in the same embedding space as a generated embedding representation of the received query.”
- The system can efficiently retrieve relevant image search results, even for long or obscure queries, by evaluating the closeness in the embedding space.
“Feature embeddings can model more general semantic relationships between features. The closeness of the numeric embeddings of the features can be trained to measure a relevance of the candidate image search result to the image search query.”
- The embedding-based retrieval system can be used alongside traditional term-based retrieval systems to enhance search result relevance.
“Retrieval in the embedding space can be computationally efficient because fast algorithms can be developed to efficiently find nearest neighbors or approximately nearest neighbors in the embedding space.”

- The system can support features like obtaining related queries or documents based on a query or a document, without the need for separate indexing and retrieval systems.
“Having queries and image-landing page pairs in the same embedding space can enable features that requires identifying relationships between different queries and different landing pages.”
- The embedding space can also relate content across different languages, leveraging the language-independent similarity of images on landing pages.
“In some implementations, an embedding space for queries and image-landing page pairs in different languages can be simultaneously learned.”
- The system is designed to narrow down the vast number of initial image search results to a much smaller, more relevant set of candidates.
“The first candidate image search results generally include much fewer candidates than the initial image search results… This is much fewer than the initial image search results, which can be thousands or millions of image search results.”
- An index database is accessed to associate image-landing page pairs with their corresponding numeric embeddings, which have been generated using a pair embedding neural network.
“Accessing an index database that associates image-landing page pairs with corresponding pair numeric embeddings that have been generated for the image-landing page pairs using a pair embedding neural network.”
- The pair embedding neural network and the image search query embedding neural network are trained jointly to minimize a loss function, which depends on the dot product between the query numeric embedding and the pair numeric embedding.
“The pair embedding neural network and the image search query embedding neural network have been trained jointly to minimize a loss function that depends on a dot product between (i) a query numeric embedding for a training image search query and (ii) a pair numeric embedding for a training image-landing page pair.”
Implications for SEO:
These insights indicate that the system is highly sophisticated in determining the relevance of image search results. It does not solely rely on direct keyword matching but instead uses an advanced understanding of semantic relationships and user interaction likelihood. This has significant implications for SEO, as it suggests that optimizing for image search will increasingly require a focus on the contextual and semantic alignment of images with user queries.
For SEO, this patent suggests that the future of image search will rely more on the semantic relationships and the contextual relevance of images to search queries rather than just metadata and alt text. SEO strategies may need to focus on the following:
- Ensuring that images are contextually relevant to the content of the landing pages.
- Optimizing landing pages to be semantically related to the images they contain.
- Considering the use of neural network-friendly structures and metadata that can be effectively processed by embedding models.
Providing search results based on a compositional query
This patent with the identifier US11762933B2 is related to search engines and especially search query processing. This patent was first published in September 2022 by Google and published in August 2023. It was published for for US, Europe, China. Inventors are Jinyu Lou, Ying Chai, Chen Ding, Lijie Chen, Liang Hu, Kelja Liu, Weibin Pan, Yanlai Huang, David Francois Huynh.
The patent introduces a method to provide search results based on a compositional query. This involves determining entity types and relationships from the query, identifying nodes in a knowledge graph, and comparing attribute values to determine resultant entity references. The system can effectively handle queries that involve relative relationships between different entity types, providing more relevant and contextual search results.

The patent discusses a technique for providing search results. This technique involves:
- Determining a first entity type, a second entity type, and a relationship type based on a compositional query.
- Identifying nodes of a knowledge graph corresponding to entity references of the first and second entity types.

- Determining an attribute value from the knowledge graph corresponding to the relationship type for each entity reference of the first and second entity types.
- Comparing the attribute value of each entity reference of the first entity type with the attribute value of each entity reference of the second entity type.
- Determining resultant entity references from the entity references of the first entity type based on the comparison.
Compositional queries, as mentioned in the patent and generally in the context of search and information retrieval, refer to queries that involve multiple entity types and their relationships. Instead of focusing on a single keyword or entity, compositional queries aim to understand and provide results based on the relationships between different entities mentioned in the query.
Here’s a breakdown:
- Multiple Entity Types: These queries involve at least two types of entity references. An entity can be anything that is singular, unique, well-defined, and distinguishable, such as a person, place, item, idea, etc.
- Relative Relationships: The entities in the query are related by some form of relative relationship. This relationship can be spatial, temporal, or any other kind of relation that connects the entities in a specific way.
Examples:
“American Banks close to Japanese restaurants”: This query involves two types of places (banks and restaurants) and indicates a relative spatial relationship (close to) without specifying a particular bank or restaurant.
“Companies that went bankrupt during an economic crisis”: This query involves companies and economic crises, with a temporal relationship (during) connecting them.
In the context of the patent, the system aims to handle these compositional queries by determining the entity types and relationships from the query, identifying relevant nodes in a knowledge graph, and then comparing attribute values to provide the most relevant search results.

For SEO and content creators, understanding compositional queries means recognizing the importance of context and relationships in content, as search engines move towards handling more complex queries that involve multiple entities and their interrelations.
Implications for SEO:
- Complex Query Handling: SEO professionals need to be aware that search engines might be moving towards handling more complex queries that involve relationships between different entities.
- Knowledge Graph Optimization: As the patent emphasizes the use of a knowledge graph, optimizing content to be recognized and categorized correctly within such graphs becomes crucial.
- Entity Recognition: Content should be structured in a way that search engines can easily recognize and categorize different entities and their relationships.
- Contextual Relevance: SEO strategies should focus on ensuring content is contextually relevant, considering the search engine’s ability to understand and compare attributes of different entities.
Mapping images to search queries
This patent with the identifier US11734287B2 is related to search engines and especially image search ranking. This patent was first filed in November 2020 by Google and published in September 2023. It was published for only for US. Expiration date is 2036. Inventors are Matthew Sharifi, David Petrou and Abhanshu Sharma.
The patent revolves around a method and system that allows users to input a query in the form of an image. The system then identifies entities associated with the image, maps these entities to pre-associated search queries, scores these queries based on relevance, and finally outputs a representative search query in response to the image input.

Key Insights:
- Purpose and Application:
- The patent is designed to process a user’s query image and provide relevant information in response to the image.
“In general, a user can request information by inputting a query to a search engine. The search engine can process the query and can provide information for output to the user in response to the query.”
- The patent is designed to process a user’s query image and provide relevant information in response to the image.
- Query Image Processing:
- The system receives entities associated with the query image. These entities can be obtained from image labels, which might be fine-grained (specific landmarks, book covers) or coarse-grained (general objects like buildings).
“The system receives one or more entities that are associated with the query image by first obtaining one or more query image labels, e.g., visual recognition results, for the query image.”
- The system receives entities associated with the query image. These entities can be obtained from image labels, which might be fine-grained (specific landmarks, book covers) or coarse-grained (general objects like buildings).
- Knowledge Graph Integration:
- For the obtained image labels, the system identifies entities using a knowledge graph. This helps in associating specific entities with the image labels.
“For one or more of the obtained query image labels, the system may then identify one or more entities that are pre-associated with the one or more query image labels, e.g., using a knowledge graph.”
- For the obtained image labels, the system identifies entities using a knowledge graph. This helps in associating specific entities with the image labels.
- Scoring and Output:
- The system scores each candidate search query based on relevance. A representative search query is then selected based on these scores and provided as an output.
“Methods, systems, and apparatus for receiving a query image, receiving one or more entities that are associated with the query image, identifying, for one or more of the entities, one or more candidate search queries that are pre-associated with the one or more entities, generating a respective relevance score for each of the candidate search queries, selecting, as a representative search query for the query image, a particular candidate search query based at least on the generated respective relevance scores and providing the representative search query for output in response to receiving the query image.”
Some more detailed Infos about the Scoring process:
- Assignment of Relevance Scores:
- Relevance scores can be assigned to candidate search queries by another system or even by a person, such as a moderator or user of the system.
“In some instances relevance scores may be assigned to the one or more candidate search queries by another system or assigned to the candidate search queries by a person, e.g., a moderator or user of the system.”
- Relevance scores can be assigned to candidate search queries by another system or even by a person, such as a moderator or user of the system.
- Contextual Matching:
- The knowledge engine determines whether the context of the received user-input query image matches a candidate search query. Based on this match, a relevance score is generated.
“The knowledge engine 260 may determine whether a context of the received user-input query image matches a candidate search query, and based on the determined match, generate a respective relevance score for the candidate search query.”
- The knowledge engine determines whether the context of the received user-input query image matches a candidate search query. Based on this match, a relevance score is generated.
- Location-based Scoring:
- The system may consider the location associated with the query image. For instance, if a photograph of “The Gherkin” building was taken near it, the system might generate higher relevance scores for queries related to “The City of London”.
“The knowledge engine 260 may determine that the received photograph 100 of The Gherkin was taken near in the vicinity of The Gherkin. In such an example, the knowledge engine 260 may generate higher respective relevance scores for candidate search queries that are related to The City of London.”
- The system may consider the location associated with the query image. For instance, if a photograph of “The Gherkin” building was taken near it, the system might generate higher relevance scores for queries related to “The City of London”.
- Natural Language Query Integration:
- If a natural language query is provided along with the query image, the system may generate relevance scores based on this query. For instance, if the image is of the “LA Lakers” logo and the text query is “buy clothing”, the system might prioritize queries like “buy LA Lakers jersey”.
“The system may then generate respective relevance scores for the candidate search queries “LA Lakers jersey” or “buy LA Lakers jersey” that are higher than relevance scores for candidate search queries that are not related to the text “buy clothing.”
- If a natural language query is provided along with the query image, the system may generate relevance scores based on this query. For instance, if the image is of the “LA Lakers” logo and the text query is “buy clothing”, the system might prioritize queries like “buy LA Lakers jersey”.
- Search Results Page Analysis:
- The system can generate a search results page using the candidate search query and then analyze this page to determine its interest and usefulness. Based on this analysis, a relevance score is assigned.
“In other examples, the knowledge engine 260 may generate respective relevance scores for each of the one or more candidate search queries by generating a search results page using the candidate search query and analyzing the generated search results page to determine a measure indicative of how interesting and useful the search results page is.”
- The system can generate a search results page using the candidate search query and then analyze this page to determine its interest and usefulness. Based on this analysis, a relevance score is assigned.
- Popularity of the Search Query:
- The system may consider the popularity of a candidate search query. A query that has been issued more times might receive a higher relevance score.
“In other examples, the knowledge engine 260 may generate respective relevance scores for each of the one or more candidate search queries by determining a popularity of the candidate search query.”
- The system may consider the popularity of a candidate search query. A query that has been issued more times might receive a higher relevance score.
- User Activity Association:
- The system can determine a user’s current activity associated with the received image and adjust relevance scores accordingly. For instance, if the user’s current activity is determined to be shopping, and they submit an image of hiking boots, the system might prioritize queries related to nearby hiking trails.
“In further implementations, generating a respective relevance score for each of the candidate search queries may include determining a user activity associated with the received image.”
- The system can determine a user’s current activity associated with the received image and adjust relevance scores accordingly. For instance, if the user’s current activity is determined to be shopping, and they submit an image of hiking boots, the system might prioritize queries related to nearby hiking trails.
In essence, the relevance scoring mechanism is multifaceted, taking into account various factors like the context of the image, associated location, natural language queries, search results page analysis, query popularity, and user activity. This ensures that the system provides the most pertinent and relevant search queries in response to an image input.
- Assignment of Relevance Scores:
- The system scores each candidate search query based on relevance. A representative search query is then selected based on these scores and provided as an output.
- Example of Operation:
-
- An example provided in the patent mentions a query image of a building named “The Gherkin”. The system identifies the building and provides a representative search query like “What style of architecture is The Gherkin?”.
“The knowledge panel 118 provides general information relating to the entity “The Gherkin,” such as the size, age and address of the building. The list of search results 116 provides search results responsive to the representative search query “What style of architecture is The Gherkin?”
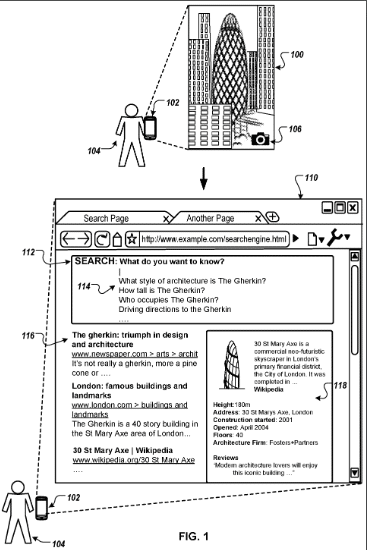

- An example provided in the patent mentions a query image of a building named “The Gherkin”. The system identifies the building and provides a representative search query like “What style of architecture is The Gherkin?”.
-
This patent showcases an innovative approach to search queries, allowing users to use images as queries and receive relevant textual search queries in return. It integrates visual recognition with search engine capabilities to enhance user experience.
Privacy-sensitive training of user interaction prediction models
This patent with the identifier US11741191B1 is related to search engines and especially search query processing. This patent was first filled in June 2022 by Google and published again in August 2023. It was published for only for US, Canada and WIPO. Expiration date is 2039. Inventor is Lukas Zilka.

The patent revolves around the collaborative training of machine learning models across multiple user devices. The primary focus is on predicting user interactions in a manner that respects user privacy. The machine learning model is designed to process inputs, which include a search query and a data element, to generate an output. This output characterizes the likelihood that a user would interact with the data element if it were presented on a webpage identified by a search result responsive to the search query.
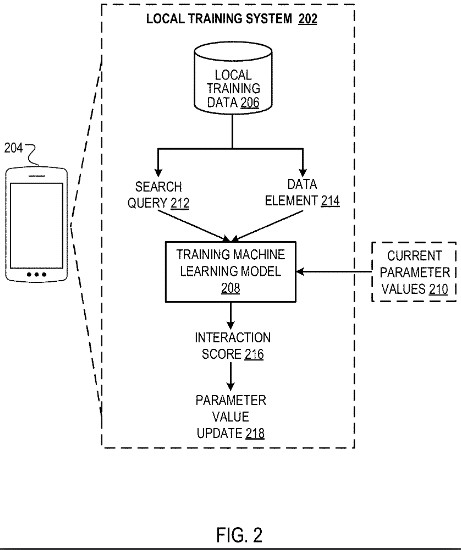
The primary goal is to determine the likelihood of a user interacting with a specific data element based on a search query. One of the standout features of this patent is its emphasis on user privacy, ensuring that the training and prediction processes do not compromise personal data. The patent showcases Google’s commitment to enhancing user experience while ensuring data privacy and security.

Key Insights:
- Collaborative Training: The patent emphasizes the collaborative training of machine learning models across multiple user devices. This collaborative approach ensures that the model is trained on diverse data from various sources, enhancing its accuracy and reliability.
Quote: “This specification relates to collaborative training of machine learning models across multiple user devices.”
- Privacy-Centric: One of the main features of this patent is its focus on user privacy. The training and prediction processes are designed to be sensitive to user privacy, ensuring that personal data is not compromised.
Quote: “Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for collaboratively training an interaction prediction machine learning model using a plurality of user devices in a manner that respects user privacy.”
- Interaction Prediction: The machine learning model is specifically designed to predict user interactions based on a given search query and data element. The output from the model provides insights into the likelihood of a user interacting with a particular data element.
Quote: “In one aspect, the machine learning model is configured to process an input comprising: (i) a search query, and (ii) a data element, to generate an output which characterizes a likelihood that a given user would interact with the data element if the data element were presented to the given user on a webpage identified by a search result responsive to the search query.”
This patent shows that Google is aiming for more usercentric personalizaition of the search results. On the other hand personalization also means to collect more personalized data and so Google has to develop approaches which respect the privacy of users. That is important because of the strict privacy policy especially in europe.
Another interesting aspect is that Google is thinking about training machine learning processes and models on users’ devices. This would guarantee a high level of personalization and save own resources. I have already observed this approach in some Google patents in recent years.
Combining content with a search result
This patent with the identifier US11727046B2 is related to search engines and especially SERP features. This patent was first filled in October 2022 by Google and published in August 2023. It was published for only for US. Expiration date is 2033.
Background:
The patent pertains to the domain of information presentation, particularly in the context of the internet. The internet provides access to a plethora of resources, such as video/audio files, webpages on specific subjects, news articles, etc. Given this vast access, there are opportunities to provide other content (like advertisements) alongside these resources. For instance, a webpage might have designated slots where additional content can be displayed. These slots can either be predefined in the webpage or can be defined for presentation alongside the webpage, especially with search results.
Quote: “The Internet provides access to a wide variety of resources. For example, video and/or audio files, as well as webpages for particular subjects or particular news articles, are accessible over the Internet. Access to these resources presents opportunities for other content (e.g., advertisements) to be provided with the resources.”

Core Concept:
The patent discusses methods, systems, and apparatus that include computer programs encoded on a computer-readable storage medium. The primary function is to provide content. When a user queries a search engine, search results are identified. Among these results, there might be a top set of results associated with a specific entity. Alongside these search results, an eligible content item (like an advertisement or additional information) associated with the same entity is identified. The system then combines the search result and the eligible content item to present it as a single search result in response to the query. This combined content item can further be augmented by identifying related entities and content items associated with them.
Quote: “Methods, systems, and apparatus include computer programs encoded on a computer-readable storage medium, including a method for providing content. Search results responsive to a query are identified… A combined content item is identified that is a combination of the first search result and first eligible content item and is to be presented as a search result responsive to the query.”

Key Insights:
- Content Augmentation: The patent emphasizes the augmentation of combined content items. This means that once a primary content item (like a search result) is combined with an eligible content item (like an advertisement), this combined content can be further enhanced by pulling in related content.
- Entity Association: The system identifies content based on its association with specific entities. For instance, if a search result is related to a particular brand or topic, the system will look for eligible content items (like advertisements) that are also associated with the same brand or topic.
- Enhanced User Experience: By combining relevant search results with associated content items, the system aims to provide a richer and more informative user experience. Instead of viewing search results and advertisements separately, users get a consolidated view where the primary content and the additional content are seamlessly integrated.

In simpler terms, imagine searching for a product on a search engine. Instead of just getting a link to the product’s official website, you might also see a special offer or advertisement related to that product directly combined with the search result.
This patent by Google aims to enhance the way users receive and view information on the internet, making the experience more integrated and contextually relevant.
Media item matching using search query analysis
This patent with the identifier US11720920B1 is related to search engines and especially search query processing in Youtube. This patent was first filled in October 2022 by Google and republished in a new version in August 2023. It was published for US and WIPO. This means that it is more likely to be used in practice. Expiration date is 2037.
Background:
The patent’s background emphasizes the role of content delivery platforms in allowing users to share various types of content, including videos, images, and audio. These platforms enable both professional and amateur content creators to upload and share their content, which can then be viewed, commented on, and shared by other users.
The patent revolves around a system and method for media item matching using search query analysis. Here’s a detailed breakdown:
- Media Item Removal: The system identifies a media item that has been removed from a media hosting platform. This removal is due to a request associated with a reference media item owned by a particular media owner.
- Search Query Identification: The system identifies a search query that corresponds to the removed media item. This identification is based on the history of search queries. Notably, the search result of this query had included the removed media item.

- Additional Media Items: The system can obtain more media items that are included in the search result of the identified search query.
- Action Initiation: These additional media items are then provided to the original media owner. The owner can then decide whether to initiate any actions regarding these additional media items.
Quote: “Asystem and method are disclosed for media item matching using search query analysis. In an implementation, the method includes identifying, by a processing device, a first media item that has been removed from a media hosting platform due to a removal request associated with a reference media item of a first media owner; identifying, by the processing device, a search query corresponding to the first media item based on a history of search queries, wherein a search result of the search query included the first media item; obtaining, by the processing device, one or more additional media items included in the search result of the search query; and providing the one or more additional media items to the first media owner to determine whether to initiate one or more actions regarding the one or more additional media items.”
The patent provides a method to manage and control media items on a hosting platform, especially when certain media items are removed due to various reasons. By analyzing search queries and user interactions, the system can identify related media items and offer them to the original media owner for further actions.
Think of this patent as a way for platforms like YouTube to manage content. If a video is removed because it’s similar to another video, this system can find other videos that might also be similar. The owner of the original video can then decide what to do with these similar videos.
Insights:
- User Interaction with Media: The patent mentions the number of users of the media hosting platform that viewed the first media item from the search result. If this number exceeds a certain threshold, the search query is selected as the identified search query.
- Factors for Media Item Selection: The patent mentions a “Factor analyzer” which is used to determine the likelihood of the additional media items matching the reference media item. This analyzer uses various factors to make this determination.When obtaining additional media items, several factors can be considered. These factors can determine the likelihood of these additional media items matching the reference media item. Some of these factors include:
- Channel age
- Channel owner
- Number of related channels of the channel owner
- Channel traffic
- Number of channel subscribers
- Channel activity
- Size of the media item
- Spam indicator
- Media item removal history
- Audio to video ratio
Quote: “In some implementations, the subset is selected in view of one or more factors associated with the one or more additional media items, wherein the one or more factors are used to determine likelihood of the one or more additional media items to match the reference media item. In some implementations, the one or more factors include at least one of a channel age, channel owner, number of related channels of the channel owner, channel traffic, number of channel subscribers, channel activity, size of media item, spam indicator, media item removal history, or audio to video ratio.”
- Scoring System: The patent suggests that an overall score can be derived from each factor associated with a media item. This score can be used when an aggregate of factors needs to be applied to the additional media item.
Quote: “The overall score may be used when an aggregate of factors are desired to be applied to the additional media item.”
Each of the factors mentioned above can be assigned a specific weight. Some factors might carry more weight, indicating their importance, while others might have less weight. An overall score is calculated by multiplying the likelihood derived from each factor associated with a media item by its corresponding weight. Optionally, this product can be divided by the total number of factors used. This overall score is then used when an aggregate of factors needs to be applied to the additional media item. In simpler terms, the scoring system is like grading a student’s performance based on various subjects. Each subject (or factor, in this case) has a certain importance (or weight), and the student’s performance in each subject contributes to the final grade (or overall score). The final grade helps in understanding the student’s overall performance, just as the overall score helps in understanding the likelihood of a media item matching the reference.
Systems and methods for machine-learned prediction of semantic similarity between documents
This patent with the identifier US11694034B2 is related to search engines and especially semantic search. This patent was first filled in October 2020 by Google and published in July 2023. It was published only for US. Expiration date is 2041.
The patent revolves around systems and methods for predicting the semantic similarity between documents. The process involves:
- Obtaining Documents: The method starts by obtaining two documents.
- Parsing Documents: These documents are parsed into textual blocks.
- Processing with a Model: Each of these textual blocks is processed with a machine-learned semantic document encoding model to obtain document encodings.
- Determining Similarity: A similarity metric is determined based on these encodings, which describes the semantic similarity between the two documents.#

Insights:
Semantic Similarity Determination:
The patent describes a “semantic similarity determinator” which can be used to determine a metric that describes the semantic similarity between two documents. This metric is based on the document encodings.
[0089] The semantic similarity determinator 410 can be used to determine a semantic similarity metric 412 descriptive of a semantic similarity between the first document 403A and the second document 403B.
Use of Cosine Similarity:
One of the methods to determine this similarity is through cosine similarity between the pooled sequence output corresponding to the document encodings.
Quote: “As an example, a cosine similarity can be determined by the semantic similarity determinator 410 between the pooled sequence output corresponding to the two documents encodings cos(E(d,), E(,)).”
Flexibility in Determining Similarity:
While cosine similarity is one method, any conventional function can be used to determine the similarity between the document encodings.
Quote: “It should be noted that although a cosine similarity can be used to determine the similarity metric 412 between the first document encoding 408A and the second document encoding 408B, any conventional function can be utilized to determine a similarity between the first and second document encodings 408A/408B.”
Hierarchical Submodel Structure:
The machine-learned semantic document encoding model uses a hierarchical submodel structure. This structure allows the model to localize dependencies between textual segments, such as sentences, within a textual block or among multiple textual blocks.
Quote: “In such fashion, by utilizing a hierarchical submodel structure, the machine-learned semantic document encoding model can localize the dependencies between textual segments (e.g., sentences) to those included in a textual block and/or among textual blocks.”

Evaluating Loss Function:
The method also involves evaluating a loss function that assesses the difference between the determined similarity metric and some ground truth data associated with the documents. This evaluation aids in adjusting parameters of the semantic document encoding model.
Quote: “evaluating a loss function that evaluates a difference between the similarity metric and ground truth data associated with the first document and the second document.”
In simpler terms, this patent describes a method to determine how similar two documents are in terms of their meaning or content. It uses a machine-learned model to process the documents and determine a similarity score, which can be adjusted and refined based on actual data.
The data used for determining the similarity score between two documents is based on their respective encodings. The similarity score is derived from the encoded representations of the documents, and various methods, including cosine similarity and other conventional functions, can be used to compute this score. This score can then be employed for various tasks, including clustering and classification. Here are the insights and corresponding quotes from the patent:
Document Encodings:
The similarity metric is determined based on the encodings of the two documents.
Quote: “[0039] A similarity metric can be determined based at least in part on the first document encoding and the second document encoding (e.g., a comparison between the document encodings, etc.).”
Cosine Similarity:
Cosine similarity is one method used to compare the pooled sequence outputs corresponding to the document encodings.
Quote: “As an example, a cosine similarity can be determined between the pooled sequence outputs corresponding to the two documents cos(E(d,), E(d,)) (e.g., the first document encoding and the second document encoding).”
Conventional Functions:
Apart from cosine similarity, any conventional function can be employed to determine the similarity between the document encodings.
Quote: “It should be noted that although a cosine similarity can be used to determine a similarity metric between the first document encoding and the second document encoding, any conventional function can be utilized to determine a similarity between the first and second document encodings.”
Binary Prediction & Percentage Metric:
The similarity metric can include a binary prediction indicating whether the two documents are semantically similar. Alternatively, it can also include a predicted level of semantic similarity between the two documents, such as a percentage metric.
Quote: “For example, the similarity metric can be or otherwise include a binary prediction as to whether the first document and second document are semantically similar. For another example, the similarity metric can be or otherwise include a predicted level of semantic similarity between the two documents (e.g., a percentage metric, etc.).”
Downstream Tasks:
The similarity metric can be further utilized for various downstream tasks, such as clustering and classifying documents.
Quote: “[0051] In some implementations, the similarity metric can be utilized for additional downstream tasks (e.g., machine learning tasks, etc.). As an example, the similarity metric can be utilized to cluster at least one of the first and second documents (e.g., k-means clustering, hierarchical clustering, etc.).”
In simpler terms, this patent describes a method to determine how similar two documents are in terms of their meaning or content. It uses a machine-learned model to process the documents and determine a similarity score, which can be adjusted and refined based on actual data.
Contextualizing knowledge panels
This patent with the identifier US11720577B2 is related to search engines and especially semantic search. This patent was first filled in January 2022 by Google and published in August 2023. The patent is a republishing and was first published in 2016. It was published for US, South Corea and WIPO. This means that it is more likely to be used in practice. Expiration date is 2038.
The patent describes a system designed by Google that provides users with a “knowledge panel” when they search for entities, like singers, actors, writers, etc. This knowledge panel provides relevant and detailed information about the searched entity based on the context of the search query.
Key Insights:
Entity and Context:
- The system can receive search requests that include the name (or identifier) of an entity and additional context terms from the user’s search query.
“A system can receive requests including identifiers of entities… as well as context terms that are referenced by a search query submitted by a user.”
Knowledge Elements:
- The system identifies multiple “knowledge elements” related to the searched entity. Knowledge elements can be facts or pieces of content related to the entity.
“Identifying a plurality of knowledge elements that are related to the entity;”
Ranking and Selection:
- The system will rank these knowledge elements based on their relevance to the context terms from the search query.
Each predicted set may have an associated confidence score or probability score indicating a level of certainty that the features provided predict the particular fixed set of entities. In some implementations, the confidence score may be based on a similarity measure which may differ depending on the type of set. For example, the confidence score for a location-based sets may be based on physical distance from a specified location, e.g., the current location of a computing device. The confidence score for a topic-based set may be based on an embedding distance with a query, such as an embedding generated based on signals from a client device. Such signals can include text recently seen on the screen, the state or proximity of external devices, content of recent searches, stated user interests, an application installed or executing on the client device, a time stamp, etc.,
- It then selects the most relevant knowledge elements to display.
“Assigning, by one or more computers, rank scores to the plurality of knowledge elements… selecting one or more of the knowledge elements from among the knowledge elements based at least on the rank scores assigned to the knowledge elements;”
Presentation in the Knowledge Panel:
- The system can decide how to present the selected knowledge elements in the knowledge panel. This includes determining the position of the knowledge panel on the search results page, the number of knowledge elements to show, their position within the panel, and even specific features like highlighting text or deciding on a title or subtitle.
“Providing information associated with the entity and the one or more selected knowledge elements comprises providing data that causes information associated with the entity and the one or more selected knowledge elements to be presented in a knowledge panel, the knowledge panel being presented with a search results page associated with the search query.” “In some implementations providing data that causes information associated with the entity and the one or more selected knowledge elements to be presented in the knowledge panel comprises determining, based on identifying the one or more context items that are associated with the entity that is referenced by the search query, a number of knowledge elements to select for presentation in the knowledge panel;”

Customization:
- The system can customize the knowledge panel based on the context of the search. This could include choosing which information to highlight, or determining a suitable title or subtitle for the displayed information.
“In certain aspects, providing data that causes information associated with the entity and the one or more selected knowledge elements to be presented in the knowledge panel comprises determining, based on identifying the one or more context items that are associated with the entity that is referenced by the search query, a title or subtitle relating to one or more of the selected knowledge elements presented in the knowledge panel…”

In essence, this patent reveals how Google aims to enhance its search results by presenting users with a tailored “knowledge panel” that provides in-depth information about searched entities, adjusted and ranked based on the context of the user’s search query.
Content selection and presentation of electronic content
This patent with the identifier US11663277B2 is related to search engines and especially News. This patent was first filled in May 2021 by Google and published in August 2023. It was published for US, Canada and WIPO. This means that it is more likely to be used in practice. Expiration date is 2038.
The patent deals with a method and system for populating an interest feed with electronic news article resources. It is obviously related to Google Discover.

Method for Populating an Interest Feed:
- The system looks for electronic news articles that reference two entities (first entity and second entity) with a significant relevance.
- If enough articles reference both entities, it’s inferred that there is an ongoing event involving both entities.
- A representation (like a news summary or highlight) of this event is generated using content from the articles and other resources.
- If a user’s interest list includes the first entity but doesn’t already have the event, this representation is provided to the user’s device.
Scoring and Selection:
- Each article is assigned scores based on how much they relate to the first and second entities.
- The system can create a “superset” of articles that mention both entities. From this, a subset is selected where each article references both entities with significant relevance.
Event Determination:
- Multiple possible events involving the two entities are identified.
- A filtering algorithm is used to shortlist the most likely events based on the articles.
- The type of the likely event can be determined using the articles.
Content Generation:
- The event representation includes content that describes the ongoing event.
- Additional content is generated based on other resources which relate to some attribute of the activity in the event.
Attributes and Additional Resources:
- Attributes might include the type of activity, the industry of the activity, a connection to a previous event, or correlation with another user’s interest list.
- Based on the correlation between the first and second entities, the system selects additional resources to provide more context or information.
User Search Queries:
- The system can also identify the first entity based on search queries from multiple users.
Key Insights with Quotes:
- Interest Feed Generation:
- The patent emphasizes creating a personalized feed for users based on trending events related to their interests.
“A method for populating an interest feed with electronic news article resources…”
- The patent emphasizes creating a personalized feed for users based on trending events related to their interests.
- Relevance Threshold:
- The system relies on a threshold of relevance to determine which articles are significant.
“…that a threshold quantity of electronic news article resources each reference both a first entity and a second entity with at least a threshold magnitude of relevance…”
- The system relies on a threshold of relevance to determine which articles are significant.
- Event Representation:
- The system generates a summarized or highlighted representation of the detected event for the user.
“generating a representation that corresponds to the event…”
- The system generates a summarized or highlighted representation of the detected event for the user.
- Additional Content:
- Content isn’t just derived from news articles. The system will seek other resources that relate to the event’s activities.
“…generating second content that is based on an additional resource…”
- Content isn’t just derived from news articles. The system will seek other resources that relate to the event’s activities.
- User’s Interest List:
- Users receive content based on their specific interests, enhancing the personalization of their feed.
“identifying a user account that includes an interest list that includes the first entity but that does not include the determined event…”
- Users receive content based on their specific interests, enhancing the personalization of their feed.

In essence, the patent outlines a sophisticated method for curating a personalized news feed for users, driven by electronic news articles, relevance scoring, event detection, and additional resources. It sounds for me like a description of a system like Google Discover.
Systems and methods that match search queries to television subtitles
This patent with the identifier US11743522B2 is related to search engines. This patent was first filled in May 2021 by Google and published in August 2023. It was published only for US. It belongs to a patent family first published in February 2017.
The patent describes a system and method for providing video program information to users.
Core Concept:
The primary goal of this system/method is to identify a spike in search queries during a specific time period and then correlate this spike to a media content item (like a video or TV show) that was presented during that time. If a user shows interest in this media content during a subsequent time period, the system will then provide search results corresponding to the original search queries to the user’s computing device.
Quote:
“A method for providing video program information, the method comprising: identifying, using a hardware processor, a search query spike from search queries during a first time period; correlating, using the hardware processor, the search query spike to a media content item being presented during the first time period…”
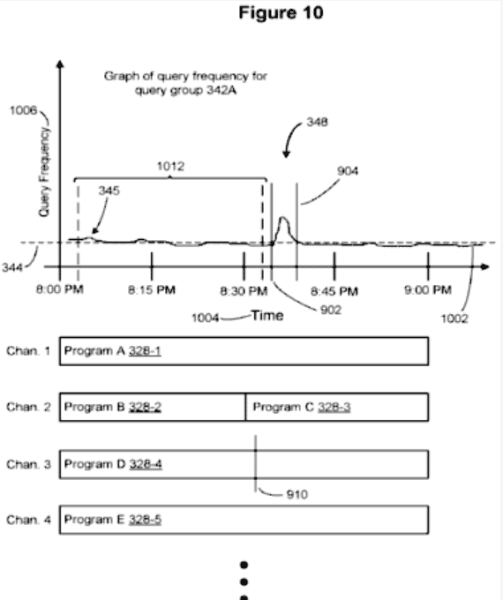
Use of Subtitles/Terms:
To establish the correlation between the search spike and the media content, the system matches search terms from the queries to subtitle terms associated with the media content item.
Quote: “…by matching a plurality of search terms from the search queries to a plurality of subtitle terms associated with the media content item…”

Search Query Equivalence:
The system can determine if two search queries are equivalent in two ways:
- If the sequence of search terms in one query is substantially identical to that in another.
- If both queries express the same linguistic concept.
Quotes:
“…a first search query and a second search query from the search queries are identified as being equivalent when an ordered sequence of search terms from the first search query is substantially identical to an ordered sequence of search terms from the second search query…”
“…a first search query and a second search query from the search queries are identified as being equivalent when a linguistic concept expressed using search terms from the first search query is substantially the same linguistic concept expressed using search terms from the second search query…”
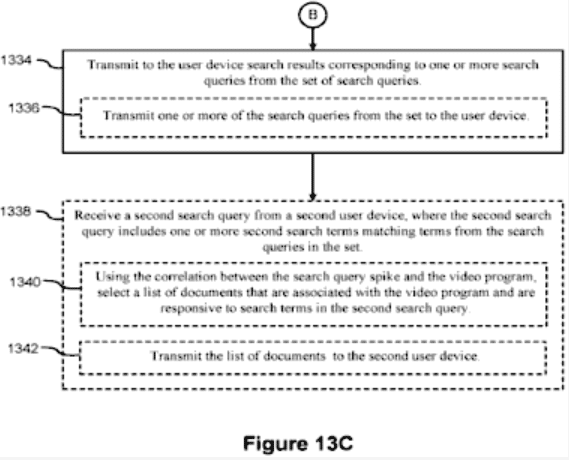
User Interest Indicators:
The method recognizes user interest in a media content item through different methods:
- Detecting that the media content is currently displayed on a device near the user’s computing device.
- Receiving an audio stream from the user’s device and correlating it to the media content.Quotes:
“…receiving the indication of user interest in the media content item from the computing device comprises receiving an indication that the media content item is currently being presented on a display device proximal to the computing device…”
“…receiving the indication of user interest in the media content item from the computing device comprises receiving an audio stream from the computing device and correlating the audio stream to the media content item…”
Second Screen Experience:
The system emphasizes the experience where the computing device (on which the user shows interest or receives information) is separate from the primary display device presenting the media content, commonly referred to as a ‘second screen’ experience.
Quote: “…the computing device is a second screen device and the media content item is presented on a display device proximal to the computing device…”
System Implementation:
The patent presents this method in various forms:
- As a method (the process itself).
- As a system (including a hardware processor in a server device).
- As a non-transitory computer-readable medium containing instructions to execute the method.
Quotes:
“A system for providing video program information, the system comprising: a hardware processor of a server device…”
“A non-transitory computer-readable medium containing computer executable instructions that, when executed by a processor, cause the processor to perform a method for providing video program information…”
The patent proposes a unique way to enhance the user experience by detecting interest in specific media content based on search query spikes and providing relevant information on a secondary device. This caters to the growing trend of multi-device usage while consuming content and the curiosity-driven nature of audiences.
This patent with the identifier US11758237B2 is related to search engines. This patent was first filled in August 2022 by Google and published in September 2023. It was published for US and WIPO. It belongs to a patent family first published in November 2011.
The patent pertains to a method where, when a user searches for something related to the content currently being shown on their media device (e.g., a TV show or movie), the system displays an overlay on the device. This overlay provides search suggestions and search results related to the media content. The results may include links to relevant channels or applications. Some of the claims expand on the method, detailing features like extracting keywords from the media content’s metadata, recognizing when the media content changes, and determining if a suggested application is already installed on the device.
Insights:
Overlay on Media Content: The core of the patent revolves around presenting search suggestions and search results as an overlay on the media content.

“responsive to the search request, causing a first portion of search suggestions and a second portion of search results to be presented on the display device in an overlay that is positioned over the media content item”
Diverse Content Types in Search Results: The search results can include different types of content like channels, applications, or web pages.
“the second portion of search results includes (i) a first search result that is associated with a channel content type… (ii) a second search result that is associated with an application content type”
“search results include a third search result that is associated with a web page content type”
Metadata Utilization: The system can identify metadata related to the media content and extract keywords to generate relevant search suggestions.
“identifying metadata related to the media content item being presented on the display device”
“extracting keywords from the identified metadata, wherein the search suggestions are generated based on the extracted keywords”
Responsive to Media Changes: The system can recognize changes in the media content and adjust the search suggestions accordingly.
“additional search suggestions are generated in the plurality of search suggestions in response to determining that a television programming change has occurred”
Application Launching and Installation: If a search result points to an application, the system can determine if the application is installed, launch it if it is, or prompt the user to install it if it’s not.
“in response to receiving a selection of the second identifier, determining whether the application has been installed”
“in response to determining that the application has not been installed, causing a prompt to install the application to be presented”

These insights provide a comprehensive overview of the patented technology. It appears to aim at enhancing the TV viewing experience by integrating responsive and relevant search capabilities directly into the media viewing interface.
Generating and/or utilizing a machine learning model in response to a search request
This patent with the identifier US2023273923A1 is related to search engines and generative AI. This patent is a continuation of former patents and was first filled in June 2023 by Google and published in August 2023. It was published only for US.
The patent discusses methods, systems, and apparatuses for utilizing machine learning models in response to user search requests. When users submit search queries that may not have definite answers, the patent proposes using trained machine learning models to predict answers. These models can be trained “on the fly” based on the search query and can be associated with content items in a search index. The patent also describes an interactive interface that allows users to interact with the trained machine learning model to obtain predicted answers.
This patent is very interesting, because for me it describes the technological implementation of the Snapshot AI answers and the answers in conversational mode within the framework of SGE.

Important Insights:
Machine Learning for Search Queries:
This specification is directed generally to methods, systems, and apparatus for generating and/or utilizing a machine learning model in response to a search request from a user.
Quote: “Implementations described herein relate to providing, in response to a query, machine learning model output that is based on output from a trained machine learning model.”
Predictive Nature of Search Queries:
For example, a user can submit a request that is predictive in nature and that has not been predicted and/or estimated in existing sources.
Quote: “However, it is often the case that none of the answers and/or documents can include a “good” answer to the user’s query.”

Interactive Interface for Machine Learning Models:
The machine learning model output can additionally or alternatively include an interactive interface for the trained machine learning model.
Quote: “For example, the interactive interface can be a graphical interface that a user can interact with to set one or more parameters on which the machine learning model is to be utilized to generate a prediction…”
Generating Machine Learning Models Based on Search Queries:
Some implementations described herein relate to generating a trained machine learning model “on the fly” based on a search query.
Quote: “For example, some of those implementations relate to determining training instances based on a received search query, training a machine learning model based on the determined training instances…”
Working Example of Predictive Queries:
As a working example of some implementations, assume a user interacts with a client device to submit a query of “How many doctors will there be in China in 2050?” to a search engine.
Quote: “However, none of these search results may provide a satisfactory answer to the user’s query.
Training Instances for Machine Learning Models:
Training instances for a machine learning model can then be generated based on the variation parameters and their corresponding values, and the machine learning model trained utilizing the training instances.
Quote: “For example, a first training instance can include training instance input indicative of the year “2010” and training instance output indicative of the quantity of doctors in China in the year “2010”…”
Interactive Interface for Predictions:
After the machine learning model is trained, machine learning model output that is based on the trained machine learning model can be provided in response to the search query.
Quote: “For instance, and continuing with the working example, the interactive interface can include an interactive field that accepts various years as input…”
Nature of Predictions:
The prediction provided as machine learning model output for presentation to the user is based on one or more predicted values generated over the machine learning model.
Quote: “In some implementations, the prediction provided for presentation is a single value, such as a single predicted quantity of doctors in China in the working example.”
This patent essentially emphasizes the potential of machine learning models to predict answers to search queries, especially when traditional search methods might not yield satisfactory results. The integration of interactive interfaces further enhances the user experience by allowing them to interact directly with the model and adjust parameters for more tailored results.
The patent discusses advanced methods and systems for utilizing machine learning models in response to search queries. Here’s a summarized breakdown:
- Machine Learning Model in Search Queries:
- The patent focuses on generating machine learning models to predict answers to search queries, especially when definite answers aren’t available.
- Instead of just providing search results, the system can predict answers or provide an interactive interface for users to get predictions based on trained machine learning models.
- On-the-Fly Model Training:
- The system can create a machine learning model “on the fly” based on a search query.
- It determines training instances from the received search query, trains a model, and then provides an output based on this newly trained model.
- Model Validation:
- After training, the model is validated to ensure its predictions meet a certain quality threshold.
- If the model doesn’t meet the threshold, its output might be suppressed, and traditional search results might be shown instead.
- Validation can use “hold out” training instances that weren’t used during the training phase.
- Interactive Interfaces:
- Users can interact with an interface to input parameters and get predictions.
- For instance, inputting different weather conditions to predict snowcone sales.
- Delayed Responses:
- Due to the “on-the-fly” training, there might be a delay between the query submission and receiving the machine learning model’s output.
- Users might receive a prompt or notification about this delay, and the results might be “pushed” to their device later.
- Model Indexing and Reuse:
- Once trained, machine learning models can be indexed by content from their training data or other related content.
- Later, if a similar query is received, the system can identify and use the previously trained model, saving computational resources.
- Technical Advantages:
- The system reduces the need for users to submit multiple varied queries.
- It offers computational efficiency by reusing trained models.
- The system can train models without human intervention and index them for future use.
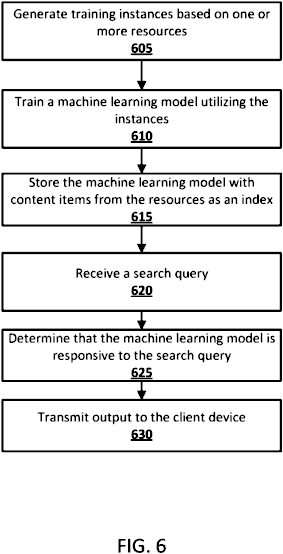
In essence, the patent introduces a dynamic way to use machine learning models in search engines, offering predictive answers and interactive interfaces, especially when definitive answers aren’t readily available.
This reminds me of what Google SGE is trying to do and I think this patent is closely related to SGE.
Structured entity information page
This patent with the identifier US11706318B2 is related to search engines and specifically to semantic and entity based search. This patent is a continuation of former patents and was first assigned 2015 by Google and newly published in July 2023. It was published for US, Germany and WIPO. This means that it is more likely to be used in practice. Expiration date is 2036.

The patent describes a method performed by a server system to generate and display a structured information page associated with an entity. When the server system receives a request from a client device for this information page, it identifies historical user activity related to the entity. The server system then generates the information page by formatting it according to predefined and dynamically selected information types. The relative importance of these candidate information types is determined by the server system. The information page is populated with the identified information and transmitted to the client device for display. Additionally, the structured information page may include primary and secondary colors associated with the entity.
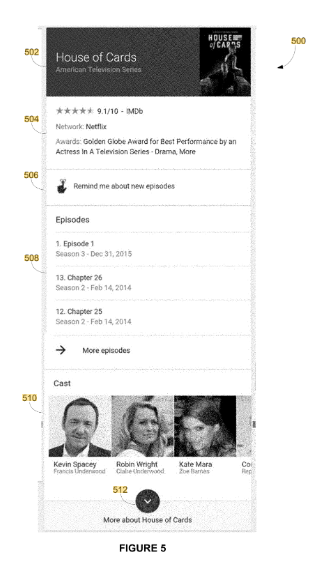
Important Insights:
- Structured Information Page Generation: The patent emphasizes a method where the server system generates a structured information page related to a specific entity.
Quote: “The patent describes a method performed by a server system to generate and display a structured information page associated with an entity.”
- Historical User Activity: The system identifies historical user activity related to the entity to tailor the information page.
Quote: “The server system receives a request from a client device for the information page and identifies historical user activity related to the entity.”
- Dynamic Formatting: The information page is formatted based on both predefined and dynamically selected information types.
Quote: “The server system then generates the information page by formatting it according to predefined and dynamically selected information types.”
- Relative Importance of Information: The server system determines the relative importance of candidate information types to populate the information page.
Quote: “The relative importance of the candidate information types is determined by the server system.”
- Color Association: The structured information page may have colors associated with the entity, potentially for branding or recognition purposes.
Quote: “The structured information page may also include primary and secondary colors associated with the entity.”
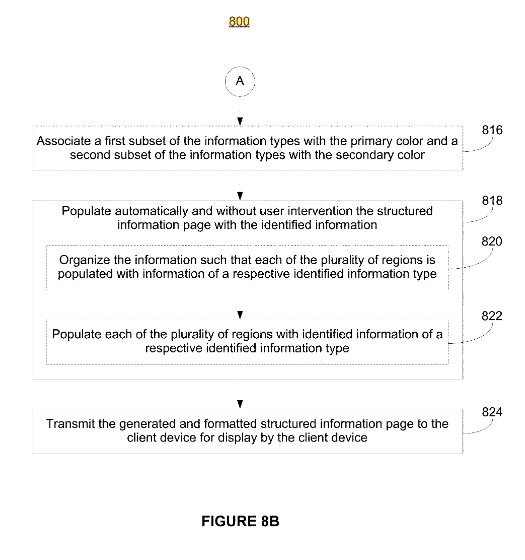
It is obvious this patent describes the methodology of serving Knowledge Panels at Google.
Both the Knowledge Panel and the patent emphasize presenting structured information about entities. While the Knowledge Panel provides summaries and key details about a topic, the patent’s method also focuses on creating a structured page with relevant information about an entity. The patent mentions the use of historical user activity to tailor the information page. Similarly, Google’s Knowledge Panel might prioritize certain information based on user behavior and search trends. (more to this topic in my article on SEL How Google creates knowledge panels).
Both systems are centered around entities. Whether it’s a person, place, organization, or thing, the goal is to provide users with a comprehensive and organized view of the topic.
The patent mentions the inclusion of primary and secondary colors associated with the entity. This is reminiscent of how Google’s Knowledge Panel sometimes includes branding or recognizable images/colors associated with the entity being searched.
In both cases, a server system processes the request and sends the structured information to the client device (usually a user’s browser) for display.
The patent US10110701B2 can be seen as a technical embodiment of some of the concepts behind Google’s Knowledge Panel. While the patent provides a method for generating structured information pages based on user activity and predefined information types, Google’s Knowledge Panel serves as a real-world application that offers users structured, relevant, and concise information about their search queries. The patent might be one of the many technological backbones that support features like the Knowledge Panel, ensuring that users receive the most relevant and structured information for their queries.
Systems and methods for using document activity logs to train Machine-Learned models for determining document relevance
This patent with the identifier US20230267277A1 is related to search engines and specifically to relevance ranking. This patent was first assigned by Google in April 2023 and published in August 2023. It was published for US and WIPO. This means that it is more likely to be used in practice.

The patent describes a computer-implemented method and system for training a machine-learned semantic matching model. This model is designed to determine the semantic similarity between two documents. The method involves:
- Obtaining two documents along with their respective activity logs.
- Using these activity logs to determine if the two documents are related.
- Inputting these documents into the semantic matching model to receive a semantic similarity value.
- Evaluating a loss function based on the difference between the determined relation (from the activity logs) and the semantic similarity value.
- Modifying the parameters of the semantic matching model based on this loss function.
The model can determine the semantic similarity by generating content embeddings for each document and then comparing these embeddings. The content of the documents can include text, images, videos, and files. The activity logs describe various access events related to the documents, such as opening, sharing, editing, and more. The relation between documents can also be influenced by the time and type of access events. The trained model can be used to rank search results based on their semantic similarity to a user’s search query.
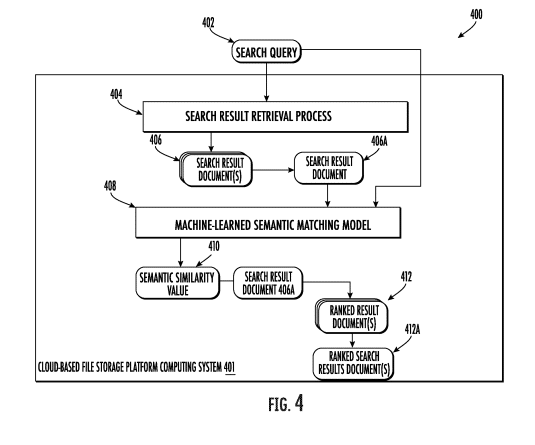
Important Insights:
Semantic Matching Model Training:
The patent focuses on training a semantic matching model to determine the relatedness of two documents.
“A computer-implemented Method for training a machine-learned semantic matching model…”
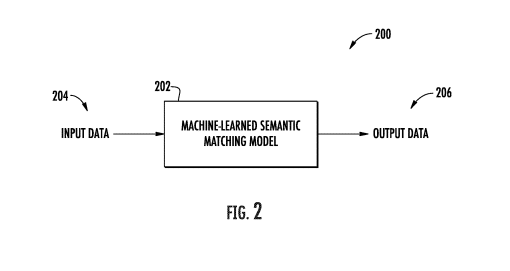
Use of Activity Logs:
The method uses activity logs associated with documents to determine if they are related.
“…a first document activity log associated with the first document, a second document, and a second document activity log associated with the second document…”
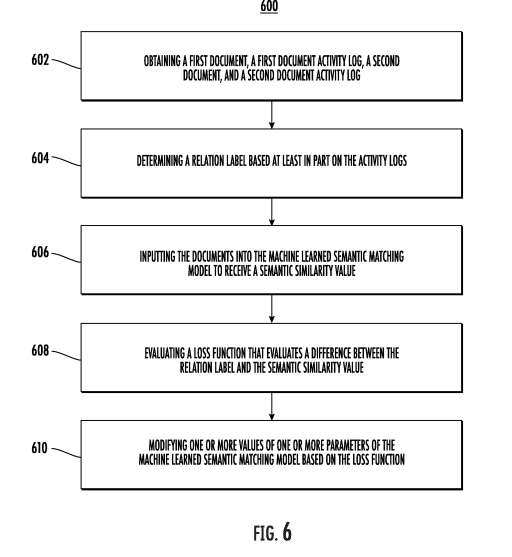
Semantic Similarity Evaluation:
The model provides a semantic similarity value, which is an estimation of how similar the two documents are in terms of meaning.
“…a semantic similarity value representing an estimated semantic similarity between the first document and the second document…”
Content Embeddings:
The model determines the semantic similarity by generating content embeddings for each document. These embeddings are essentially numerical representations of the content. By comparing the embeddings of two documents, the model can estimate their semantic similarity.
“…determining a first content embedding for the first document based on at least a portion of content of the first document; determining a second content embedding for the second document based on at least a portion of content of the second document; and generating, based on the first content embedding and the second content embedding, the semantic similarity value representing the estimated semantic similarity between the first document and the second document.”
Diverse Content Types:
The documents can contain different types of content, including text, images, videos, and files. The model is capable of generating embeddings for these diverse content types, which means it can determine the similarity between documents containing any of these types of content.
“…content of the first document and the content of the second document respectively comprise at least one of: first image data and second image data; first video data and second video data; first textual data and second textual data; or first file data and second file data…”
Textual Embedding Process:
For textual content specifically, the patent describes a method to determine embeddings. This involves selecting character subsets from the text based on their appearance frequency. These subsets are then averaged to determine the textual embedding. By comparing the textual embeddings of two documents, the model can estimate the semantic similarity between them.
“…selecting one or more character subsets from the textual data of the corresponding document based at least in part on an appearance frequency for each character subset of a plurality of character subsets of the textual data of the document; and averaging the one or more character subsets to determine the textual embedding.”
Activity Log Details:
- The activity logs capture various events related to the documents, such as sharing, opening, renaming, and more.
“…the access type comprises: a document sharing event; a document opening event; a document renaming event…”
Search Result Ranking:
- The trained model can be used to rank search results based on their semantic similarity to a given search query.
“…ranking, by the one or more computing devices, based on the second semantic similarity value, the search result document among a plurality of ranked search result documents corresponding to the search query…”

System Implementation:
- The patent also describes a computing system that can determine semantic similarity between documents using the trained model.
“A computing system for determining semantic similarity between documents…”
Textual Embedding Process:
- For textual content, embeddings are determined by selecting character subsets based on their appearance frequency and then averaging them.
“…selecting one or more character subsets from the textual data of the corresponding document based at least in part on an appearance frequency for each character subset…”
Query composition system
The patent “Query completions” with the identifier US20230244657A1 is related to search engines and specifically to search query processing. This patent was published by Google in August 2023. It was published for US, Russia, China, Spain and WIPO. This means that it is more likely to be used in practice.
The patent specification pertains to the selection and provision of query suggestions to a user device. Instead of waiting for a user to type in a search query, the system can present context clusters based on the user’s context (like location, date, time, preferences) when they initiate a search. These context clusters group related queries (e.g., related to movies) and can be shown to the user even before they type anything. The user can then select a context cluster, and a list of related queries from that cluster will be presented as options. The system determines the probability of a user selecting a particular context cluster based on various factors, ensuring that the most relevant queries are presented to the user.

Important Statements:
- Context Clusters: “This specification relates to selecting and providing query suggestions to a user device… one or more context clusters (e.g., “movies”) may be presented to the user for selection input prior to the user entering any query input.”
- Creation of Context Clusters: “In general, one innovative aspect… storing, in a data storage system accessible by the data processing apparatus, data describing the context clusters and the context cluster probabilities.”
- Receiving User Context: “Another innovative aspect of the subject matter… display a context cluster selection input that indicates the selected context cluster for user selection.” [Citation: [0005]]
- Advantages: “Implementations of the subject matter described below allows for the user to provide a search query without being required to input any characters… selectable by the user without a query input by the user.”
- Details of Context Clusters: “Each context cluster includes a group of one or more queries… users’ informational needs are more likely to be satisfied.”
This patent essentially introduces a method to streamline the search process by presenting users with relevant query suggestions based on their context, even before they start typing, enhancing the user experience and making the search process more efficient.
Query completions
The patent “Query completions” with the identifier US11693863B1 is related to search engines and specifically to the generation of query completions. This patent was first drawn by Google in 2020 and published in July 2023. It was only filed in US.

The patent describes a system that uses a general-purpose action prediction engine to rank query completions based on how likely the query completions are to co-occur, in records of user activity of many users, with a query previously entered by the user. A reference query can be used to search the records of user activity to identify likely query completions.
“Ranking query completions based on queries that are highly likely to co-occur with a previous query can provide users with more relevant and more personalized query completions. Users may also see useful queries that they would not have otherwise seen.”
The system receives a query prefix from a user, obtains a reference parameter for the user, identifies one or more likely queries that are likely to co-occur with the reference parameter in user activity sessions, determines a ranking of the one or more likely queries according to the prediction scores, and provides the ranking of the one or more likely queries in response to receiving the query prefix.
In general, one innovative aspect of the subject matter described in this specification can be embodied in methods that include the actions of receiving a query prefix from a user; obtaining a reference parameter for the user; identifying one or more likely queries that are likely to co-occur with the reference parameter in user activity sessions, wherein each likely query has an associated prediction score; determining a ranking of the one or more likely queries according to the prediction scores; and providing the ranking of the one or more likely queries in response to receiving the query prefix.
“The ranking factor R is given by R = P(x|q) / P(x), wherein P(x|q) is a measure of a likelihood of the likely query x occurring in an activity session given that the reference parameter q also occurred in a same activity session, and P(x) is a measure of the likelihood of the likely query x appearing in an activity session.”
The patent also describes a system architecture that includes a search system front-end, a search engine, a query completion engine, a verification engine, and a prediction engine. The prediction engine identifies likely queries by analyzing a large collection of activity sessions in a session database. The query completion engine then ranks the query completions that will be provided to the user device by combining scores computed by the prediction engine and by the initial scores received from the verification engine.
The query completion engine then ranks the query completions that will be provided to the user device by combining scores computed by the prediction engine and by the initial scores received from the verification engine. For example, the query completion engine can promote likely queries that have high initial scores. Thus, the query completions provided to the user device are more likely to include query completions that are likely to co-occur with the user’s previous query in user activity sessions.
“The query completion engine 260 can provide the previous query 217 to a prediction engine 280 in a request to obtain likely queries 218. The prediction engine 280 may also receive the previous query 217 from another module in the search system 230, e.g., from the search system front-end 240, from the search engine 250, or from the query database 262.”
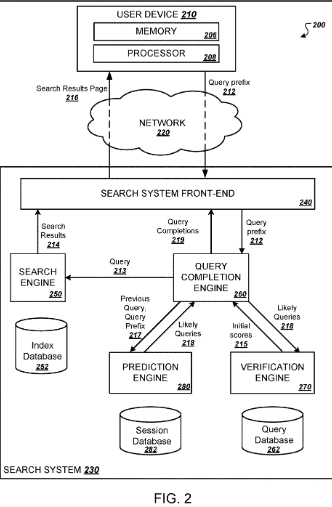
This system aims to provide users with more relevant and more personalized query completions, and users may also see useful queries that they would not have otherwise seen.
The release of this patent shows how Google could create Autosuggests for queries in general and personalized to a user based on historical user data and prediction.
Surfacing unique facts for entities
This patent was first drawn by Google in 2016 and renewed in January 2023. Since the patent has been filed in the USA, Europe, China and worldwide, it is likely that Google will use it in practice.
The patent describes systems and methods for identifying and providing interesting facts about an entity. The inventors are Akash Nanavati, Aniket Ray and Torsten Rohlfing, and the applicant is Google Inc . The patent was published on January 31, 2023 .
The patent is about the extraction of facts from unstructured data. (more about this also in the articles How Google can identify and interpret entities from unstructured content and Natural Language Processing to build a semantic database.) and serving facts about entities in the SERPs.(more about in the article How does Google understands search terms by search query processing? )
The patent describes systems and methods for identifying and providing interesting facts about an entity. An example method includes selecting documents associated with at least one unique fact trigger from a document repository.
The method also includes generating entity-sentence pairs from the documents and, for a main entity of the entities represented by the entity-sentence pairs, clustering the entity-sentence pairs for the main entity using salient terms that occur in the sentence.

This means that the entity-sentence pairs for a given entity are clustered based on the salient terms that occur in the sentences. The goal of clustering is to group similar entity-sentence pairs together to identify the most relevant and interesting facts about the entity.
“In some implementations, the unique fact finder 115 may filter out sentences that are likely already represented in the knowledge base 190 as structured facts. For example, sentences that match certain patterns, such as “X is friends with,” “X is married to,” or “X was born on” where X represents the entity mention, may be removed from the entity-sentence pairs because these sentences do not likely represent unique facts. Rather, such sentences represent structured facts. The patterns for identifying sentences that are likely structured facts may be hand curated and stored as part of the system 100.”

Which entity-sentence pairs are selected can be based on the topicality of the source document, pagerank of the document, length of the sentence, number of characters or a promotion factor of the source document that is based on links, among other things.
“Another factor may be a promotion factor that measures the fun-quotient of the source document. For example, the more inbound links for the source document that include whitelisted trigger phrases or synonyms of the whitelisted trigger phrases, the higher this promotion factor is. “
A low IDF score or rating by a rater can also be a factor.
“The IDF score represents how rare a term is across a corpus of documents, thus terms that occur less frequently across the corpus have a higher IDF score than very common terms. The IDF score for a sentence may be a demotion factor where low IDF scores represent a demotion. In some implementations, one or more of the entity-sentence pairs may be rated by an external rater (a human) for an interestingness factor.”
The topicality of a document in relation to the main entity describes the importance of the entity for the document.
“For example, if the source document for the sentence about cat urine is about cats, the entity cat will have a high document topicality score and urine will be lower. If, however, the document is about urine, the urine entity will have a higher document topicality score.”
In addition, a Semantic Importance Score can be taken into account, which measures the topicality of the entity for the sentence.
“For example, the source document may be about cats, but a sentence may compare a unique fact about a dog to cats, e.g., “a dog’s sense of smell is 100× more sensitive than a cat’s”. The semantic importance score of the The topicality score for an entity-sentence pair may be determined based on the document topicality score, the semantic importance score, or a combination of these.”
The frequency of facts mentioned in relation to an entity seems to be an indication of correctness.
“Clustering enables the system to avoid showing duplicate or near duplicate facts in a search result and enables the system to accumulate support across sentences expressing the same fact, which is an indication of a fact’s correctness and uniqueness.”
Similar terms can be assigned to a cluster via lemmatization, a sub-step of natural language processing.
The method also includes determining a representative set for each of the clusters and providing at least one of the representative sets in response to a query identifying the main entity.
Google could use these representative sentences for the knowledge panel or a kind of featured snippet.
Another example method includes determining that a query relates to an entity in a knowledge base, determining that the entity has an associated unique fact list, and providing at least one of the unique facts in the list in response to the search query.
The patent also speaks explicitly of a document repository, which is obviously a classic search index.
“For example, document repository 195 may include an index that stores terms or phrases that appear in the documents, as well as the content of the documents or a pointer to the content. In some implementations the document repository 195 represents documents available over the Internet .”
There are also some interesting statements in the patent about the general selection of sources. This describes how blogs or forums are used less as a source for facts, as they are more about opinions than facts.
Sources that stand out due to duplicate content or replication are also not considered as sources.
“Likewise documents classified as blogs or forums may be considered low-quality. Blogs and forum are likely to include more opinions than facts and less likely to have reliable facts. The system may also consider documents classified as syndicated or plagiarized as low quality. The content of documents classified as syndicated or plagiarized is duplicated from other documents.For example, a web site may be a collection of news stories from news organizations.The system may consider such documents as lacking original content and, therefore, low-quality.Another criteria used by the system to identify low-quality documents may be blacklisting.For example, a document or a domain may be added to a list and any documents in the list (e.g., specifically identified or matching a domain) are considered low-quality . Such a list may be manually curated. The system may ignore low-quality documents so that they are never considered as unique fact sources.”
Fact triggers can be unique unusual information. Trigger terms can be here:
- did you know
- fun facts
- Interesting Facts
Link texts with these terms can also be beneficial. While these terms can promote whitelisting of the documents, there are
words like
- Lie
- myths
that may encourage blacklisting.

It is interesting that the patent obviously talks about a Knowledge Graph, which assigns text or other information to entities in addition to attributes. (I described this in more detail in the article ….).
“In some implementations, the knowledge base 190 may be a data graph, where entities are stored as nodes and facts are stored as relationships between entities or attribute-value pairs for the entities. The edges may be labeled edges and the labels may represent thousands or hundreds-of-thousands of different facts. As used herein, entity may refer to a physical embodiment of a person, place, or thing or a representation of the physical entity, e.g., text, or other information that refers to an entity.”
This patent give some interesting insights how Google could identify and serve facts about entities and show that a knowledge graph is still important for Google.

Most Interesting Google patents of the last years
Here further interesting Google Patents of the last years:
Distance based search ranking demotion
The Google patent “Distance based search ranking demotion” was drawn in 2018 and published in September 2022. There were various prior versions dating back to 2018 and 2020. The oiginal patent is from 2015. The patent has a scheduled expiration date of 2035. There are signings for the patent in US, Spain, Germany and China. This makes it very likely that the patent will be used.
The patent is about ranking local documents in relation to local search queries. More precisely, it is about the downgrading of documents when it is far away from the location of the terminal on which the search is performed.
A local search result document is a “distant” search result document when the location associated with the local search result document is determined to not meet a proximity threshold. A proximity threshold may be met, for example, when the location for the local search result document and the location for the user device are within a same geographic region (e.g., a same state), or within a threshold distance (e.g., 100 miles).
Documents that are too far away from the user’s location or do not serve a local search intention or do not have a sufficient ranking score are downgraded.
Two ranking components are described in the patent. An information retrieval score and an authority score.
The search results are ranked based on scores related to the resources identified by the search results, such as information retrieval (“IR”) scores, and optionally a separate ranking of each resource relative to other resources (e.g., an authority score).
Possible ranking criteria for local documents are included addresses or frequent calls from users from the region in relation to users outside the region. The rating is determined by a ranking subsystem for local search results.
For example, the local result subsystem 120 may determine a document is a local document if the document includes an address; or if search results for the document have a high rate of selection from user devices in a given location relative to user devices outside of the particular location; or if the local document has been specified by the publisher as being local to a particular location; etc.
Excitingly, the patent describes that for local search queries that include a geographic identifier such as city, zip code or similar, the distance to the user’s location is not as important.
For such queries, search result documents that are local to the location specified by the location phrase may be determined to be more relevant than search result documents that are not local to the location. In particular, the location of the user device may be determined to be of little, if any, relevance, as the user has explicitly specified a location.
As soon as the search query has an implicit local search intention, i.e. no geopgraphic identifier explicitly appears in the search query, but there is still a local search intention, the distance to the user plays an important role.
However, if the query does have an implicit local intent, and is not an explicitly local query, e.g., such as the query “coffee shops,” then the local result subsystem 120 performs a distance adjustment process 122.
An implicit local search intent can be determined via user behavior.
A downgrading of results can take place if the ranking score does not reach a certain threshold or the object described in the document is too far away from the user. Depending on the degree of locality of the search query, non-local documents can also rank, but can also be pushed down a few places by documents with better local relevance.
The process 200 adjusts the search score of the local document eligible for demotion to demote its ranking in the first order so that the rank of the demoted local document relative to the rank of the sufficiently ranked non-local document is decreased. In some implementations, the demotion can be such that the demoted local document is ranked at least one position below sufficiently ranked non-local document.
If the local object described in a document is too far away, it can also lead to a downgrade. The distance from the user plays a role here. If local objects are too far away from the user, they are not ranked. The maximum distance to the user differs depending on the object. When searching for a restaurant, the distance will be smaller than when searching for a hospital.
Search result ranking and presentation
The Google patent “Search result ranking and presentation” was drawn in 2019 and published in August 2022. There were various prior versions dating back to 2012. The patent has a scheduled expiration date of Aug. 16, 2032. The patent describes the basic features of a semantic or entity-based search.
„In some implementations, a computer implemented method for providing search results comprises determining, using one or more processors, an entity reference from a search query. A ranked list of properties associated with a type of the entity reference is identified based on a knowledge graph. A property for generating a presentation of search results from the ranked list of properties is identified, based at least in part on the search query and on the type of the entity reference.“
„In some implementations, a computer implemented search method for search comprises identifying a modifying concept based on a search query. A rule for ranking search results is determined based at least in part on the modifying concept and on a knowledge graph from which at least one of the search results was obtained. Search results are ranked based at least in part on the rule.“
The patent addresses the fact that search queries require different display formats in addition to a list of links as a response.
„In some implementations, it may be desired to present search results using a technique that reflects the content of the search query, the content of the search results, or both. For example, it may be useful for the search system to present search results that include geographic locations on a map, and to present search results that include chronological dates on a timeline. For example, a search results for the search query “Cities in California” may automatically be presented on a map, while search results for the search query “Paintings by Van Gogh” may be presented in an image gallery view.“
For search queries such as “the tallest building”, it is useful to output a listing of the entities with the largest values for the “height” property.
In an example, where search query block 102 includes the search query “Tallest Building,” the search system may retrieve a collection of buildings from data structure block 104 and/or webpages block 110, determine that the sorting property is “Height,” and may output a ranked list of buildings by height to ranked search results block 108.
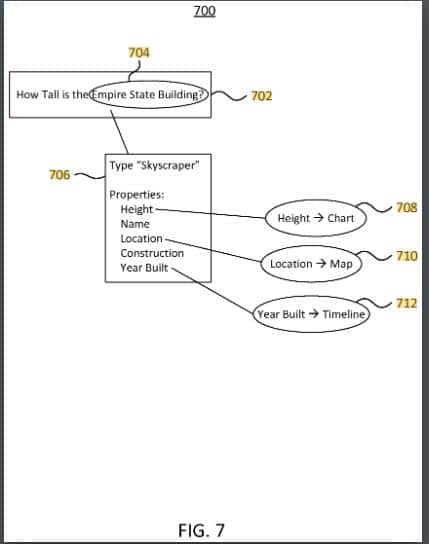
In addition, it is pointed out that it is partly necessary to access data from a structured database in order to create the search results. This can be a knowledge graph, for example.
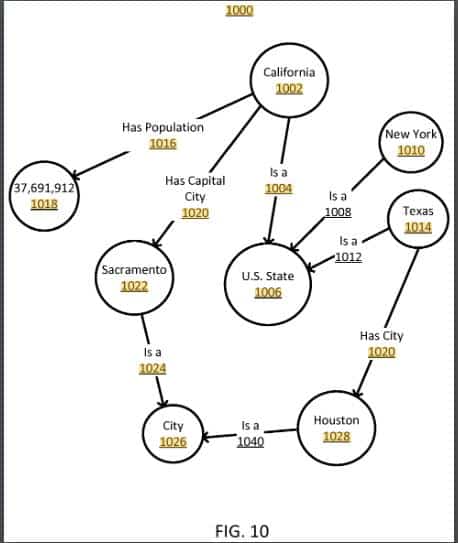
„Data structure block 104 includes a data structure including piece of information defined in part by the relationships between them. In some implementations, data structure block 104 includes any suitable data structure, data graph, database, index, list, linked list, table, any other suitable information, or any combination thereof. In an example, data structure block 104 includes a collection of data stored as nodes and edges in a graph structure. In some implementations, data structure block 104 includes a knowledge graph.“
The graphic from the patent has similarities to a graphic I created showing the interaction between the classic search index and the Knowledge Graph. In this graphic the interface between the two databases is called “Processing Block”. In my graphic I call it Entity Processing that could be built on the foundation of hummingbird.

The Processing Block is used to create entity references to the search query. This is done by Natural Language Processing.

„The search system determines an entity reference from the search query by parsing, by partitioning, by using natural language processing, by identifying parts of speech, by heuristic techniques, by identifying root words, by any other suitable technique, or any combination thereof. In some implementations, the entity reference includes text or other suitable content referencing any suitable topic, subject, person, place, thing, or any combination thereof.“
The modifiers shown in the graph can be e.g. superlatives like best, oldest, highest ….
More about this in my article HOW DOES GOOGLE UNDERSTAND SEARCH TERMS BY SEARCH QUERY PROCESSING?
An entity reference is the concept to a real world thing. The Processing Block creates a list of ranked properties of the entity.
Additionally, the entity’s properties can be enriched with other formats such as links, images, and videos.
„In some implementations, ranked search results, presentation techniques, or both, are output to ranked search results block 108. In some implementations, search results include, for example, entities from data structure 104, other data from data structure 104, a link to a web page, a brief description of the target of the link, contextual information related to the search result, an image related to the search result, video related to the search result, any other suitable information, or any combination thereof.“
If a search query can refer to multiple entity references, a Popularity Score per entity is taken into account. The most popular entity is prioritized in the delivery of search results.
„In some implementations, the search system selects one of the more than one identified entity references based on a global popularity score of that entity reference, a relevance and/or closeness to some or all elements of a search query, user input, user history, user preferences, relationships between the entity references as described in a data structure, any other suitable information, or any combination thereof. „
Read more in my articles How Google creates knowledge panels (SEL) and KNOWLEDGE PANELS & SERPS FOR AMBIGUOUS SEARCH QUERIES
It is exciting that the patent describes that not only entities, but also complete lists can be stored in the Knowledge Graph, which can then be delivered directly upon search query.
„In some implementations, the ranked list of properties is stored in a data structure such as a knowledge graph, in a database, in any other suitable data storage arrangement, or any combination thereof. In some implementations, a schema table is preprocessed. In some implementations, the ranked list is predetermined, is based on the received search, or any combination thereof.“
The ranking of the lists can be based on the following:
- Popularity
- search history
- User habits
- Input from developers
- Trends in general search behavior
- Recent search patterns
- Content
- Domain related ranking
This ranking takes place in the Processing Block or Entity Processing in my words.


The relationships between entities can be established using a “phrase tree”. The phrase tree is a theoretical construct that represents the relationships between entities.

This Google patent was published 07.05.2022 and filed on 06.08.2020. This Google patent is for me one of the most exciting in 2022. It is only registered in the US and China. It is therefore unlikely that it is currently in international use. But still exciting!

It describes a methodology how a search engine automatically suggests further links and search query alternatives within a box based on the dwell time in the SERPs. The appearance of these suggestions is reminiscent of the “others also searched for” suggestions when you return to the SERP after clicking on a search result.
It seems to be oriented to this functionality and to integrate more suggestions like links into the SERP. The difference to the already known functionality here is that not a click on a search result is the triggering event, but the dwell time.
“Implementations use a dwell signal to display related suggested items and/or to influence “next page” search results for dynamic pagination. For example, some implementations may calculate related suggestions for a search result presented in response to a query. The suggestions may include refined queries and/or links to specific items. “

If a threshold value for a dwell time is reached, a box with suggestions is automatically displayed, because it can be assumed that the user has not found what he is looking for.
The suggestions are intended to make the user direct the search queries in a slightly different direction and suggest similar content of the same category or class.
In addition, or instead, the suggestions may offer tangential suggestions that take the user in a slightly different direction, e.g., offering related queries, alternate interpretations of the query terms, and/or documents in a same category/classification as the particular search result but not highly similar to the result.
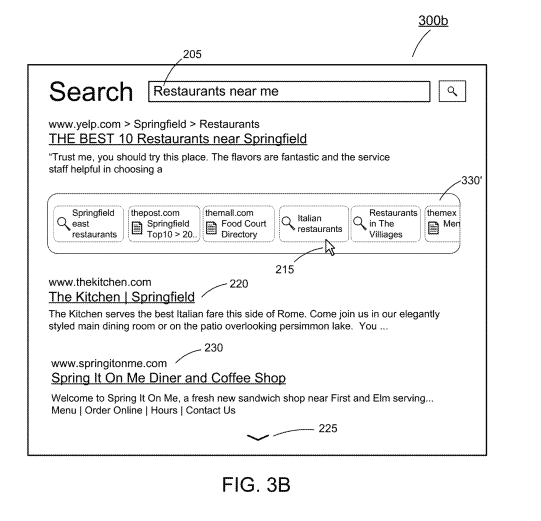
Besides links and search query refinement, the suggestions can also consist of images, videos, PDFs, audios … include. Entities can also be suggested.
In finding responsive items, the query system 120 may be responsible for searching one or more indices, represented collectively as item index 140. The item index 140 may include a web document index, e.g., an inverted index that associates terms, phrases, and/or n-grams with documents. Web documents can be any content accessible over the Internet, such as web pages, images, videos, PDF documents, word processing documents, audio recordings, etc. The item index 140 may also include an index of entities, for example from a knowledge base or knowledge graph

It is also interesting to note that suggestions can be generated based on the user journeys of other searchers.
In some implementations, the suggested follow-on queries may be related to a specific responsive item. For example, the responsive item may be associated with one or more queries, e.g., because the responsive item has been selected often after being presented as a search result for the related queries. If the responsive item has related queries these queries may be included as suggested items for the responsive item. For example, the suggested items 135 can include parts of a topic journey that other users have taken. For instance, if the current query is “jobs in Pittsburgh” the search system may suggest “housing in Pittsburgh” or “best elementary schools in Pittsburgh” as a suggested item 135.
Refinement suggestions are issued for ambiguous search queries based on other interpretations of the search query. Or in the form of terms with similar meanings, or in the form of explicit questions that illuminate a new perspective.
As another example, the suggested items 135 may include alternate interpretations of a query term. For instance, the query “jaguar” may result in “jaguar car,” “jaguar cat,” and/or “jaguar team” as suggestions. Similarly, suggested items 135 may include alternate possibilities. For example, a query of “washing machine” may have as suggested items 135 “new washing machine” or “washing machine repair” while a query of “university” may include “trade school” or “journey program” as a suggested item 135. Another example of suggestions tangential to a query are alternate viewpoints. For instance, a query of “How long should I foam roll after running?” may have as a suggested item “Should I foam roll after running?” or “Alternatives to foam rolling after running.”
In addition to the suggestions in a box, a “Next page” function can be used to offer the user to refresh the search results completely, or at least the first ten, without having to load a completely new set of hundreds of results.
The next page may include another small set of results, which may include some of the original smaller set that were not included in the first page as well as results added due to the dwell score signals. Thus, implementations may support dynamic pagination of search results and use a dwell score (or scores) to determine which search results are provided next. Dynamic pagination may be utilized irrespective of manual pagination; in other words, the user may interact with a “next page” type UI element or via automatic in-line pagination, which appends new results to the existing page.
The advantage would be a faster display of search results.
Accelerated large scale similarity calculation
This Google patent was first published in 2019 and republished on 2022-05-07.

The patent describes the process for determining a similarity of two entities based on the similarity of attributes. The degree of similarity is determined by a similarity score. The purpose of this process is to determine a response to a query.
“For example, the query might seek information indicating which domain names 20-year-old males in the U.K. find more interesting relative to the general population in the U.K. The system computes the correlations by executing a specific type of correlation algorithm (e.g., a jaccard similarity algorithm) to calculate correlation scores that characterize relationships between entities of the different datasets.”
Googles machine Learning platform Tensorflow is used as the basis for determining the similarity score.
“The system includes a tensor data flow interface that is configured to pre-load at least two data arrays (e.g., tensors) for storage at a memory device of the GPU.”

For example, a Knowledge Graph and/or the Knowledge Vault or any kind of semantic database can be used as the entity database accessed by the algorithm.
The following example from the patent shows possible entities and attributes for a comparison:
“For example, entities of one dataset can be persons or users of a particular demographic (e.g., males in their 20’s) that reside in a certain geographic region (e.g., the United Kingdom (U.K.)). Similarly, entities of another dataset can be users of another demographic (e.g., the general population) that also reside in the same geographic region.”
The exciting thing about the patent is that in addition to outputting search results, it can also be used to create groups or cohorts of similar users for Google Analytics, for example. You can find these sections in the patent:
“For situations in which the systems discussed here collect and/or use personal information about users, the users may be provided with an opportunity to enable/disable or control programs or features that may collect and/or use personal information (e.g., information about a user’s social network, social actions or activities, a user’s preferences or a user’s current location). In addition, certain data may be treated in one or more ways before it is stored or used, so that personally identifiable information associated with the user is removed. For example, a user’s identity may be anonymized so that the no personally identifiable information can be determined for the user, or a user’s geographic location may be generalized where location information is obtained (such as to a city, ZIP code, or state level), so that a particular location of a user cannot be determined.
System 100 is configured to analyze and process different sources of data accessible via storage device 106. For example, CPU 116 can analyze and process data sources that include impression logs that are interacted with by certain users or data sources such as search data from a search engine accessed by different users. In some implementations, entities formed by groups of users, or by groups of user identifiers (IDs) for respective users, can be divided into different groups based on age, gender, interests, location, or other characteristics of each user in the group.”
“In some implementations, hosting service 110 represents an information library that receives and processes queries to return results that indicate relationships such as similarities between entities or conditional probabilities involving different sets of entities. For example, a query (or command) can be “what are all the conditional probabilities associated with some earlier query?” Another query may be related to the conditional probabilities of all the ages of people that visit a particular website or URL. Similarly, another query can be “what are the overlapping URL’s visited by 30-year-old females living in the U.S. relative to 40-year-old males living in the U.K.?”
This Google patent shows that similarities and thus relationships between entities are important to Google and that attributes are the basis for determining these. It also shows that organizing around entities in terms of Internet users can also be a solution to the privacy challenges of building cohorts of similar users based on certain attributes.
Methods, systems and media for providing a media search engine
This Google patent was first published in 2011 and republished on 2022-08-02 under a new patent number. The status is active and the anticipated expiration is january 2031. It is classified in Operations research or analysis, machine learning and Marketing, e.g. market research and analysis, surveying, promotions, advertising, buyer profiling, customer management or rewards; Price estimation or determination.

This patent describes how an algorithm is trained via supervised machine learning using various methods (logistic regression, support vector machines, Bayesian approaches, decision trees, etc.) in order to classify the content. Content is labeled by people in order to then make it available to a learning algorithm as sample training data. It should be noted that these learning approaches are useful in situations when the classes considered are significantly biased (pornography or adult content, children’s content, hate speech, bombs, weapons especially, ammunition, alcohol, offensive language, tobacco, spyware, unwanted code, illegal drugs, downloading music, certain types of entertainment, illegality, profanity, etc.) and where there are limited resources to get information from people.
In addition, the approaches can be used to prevent the display of advertising on critical pages or content. Classification can be based on URL, text, anchor texts, DMOZ categories, third party classification, images on a page…
This patent provides approaches that Google uses to evaluate E-A-T, or classify, websites for spam, scam, or other content that Google does not want indexed.
- Interesting Google patents for search and SEO in 2024 - 3. April 2024
- What is the Google Shopping Graph and how does it work? - 27. February 2024
- “Google doesn’t like AI content!” Myth or truth? - 19. February 2024
- Most interesting Google Patents for semantic search - 12. February 2024
- How does Google search (ranking) may be working today - 4. February 2024
- Success factors for user centricity in companies - 28. January 2024
- Social media has become one of the most important gatekeepers for content - 28. January 2024
- E-E-A-T: Google ressources, patents and scientific papers - 24. January 2024
- Patents and research papers for deep learning & ranking by Marc Najork - 21. January 2024
- E-E-A-T: More than an introduction to Experience ,Expertise, Authority, Trust - 4. January 2024