

















Natural language processing to build a semantic database
This article is a short introduction to the topic of an entity based index relevant to search engines.
Contents
The Knowledge Graph as an Semantic databases or entity index in graph form
The entities in a semantic database such as the Knowledge Graph are captured as nodes and the relationships are mapped as edges. The entities can be augmented with labels to, for example, entity type classes, attributes, and information about content related to the entity and digital images such as websites, author profiles, or profiles in social networks.
Below is a concrete example of entities that are related to each other for clarification. The main entities are Taylor Swift and Joe Alwyn. Sub-Entities in this context are her mother Andrea Swift, his brother Patrick Alwyn or the film Arriett.
Google also identifies and stores
- associated attributes
- representations for the entities
- entity types
- documents, videos, podcasts …
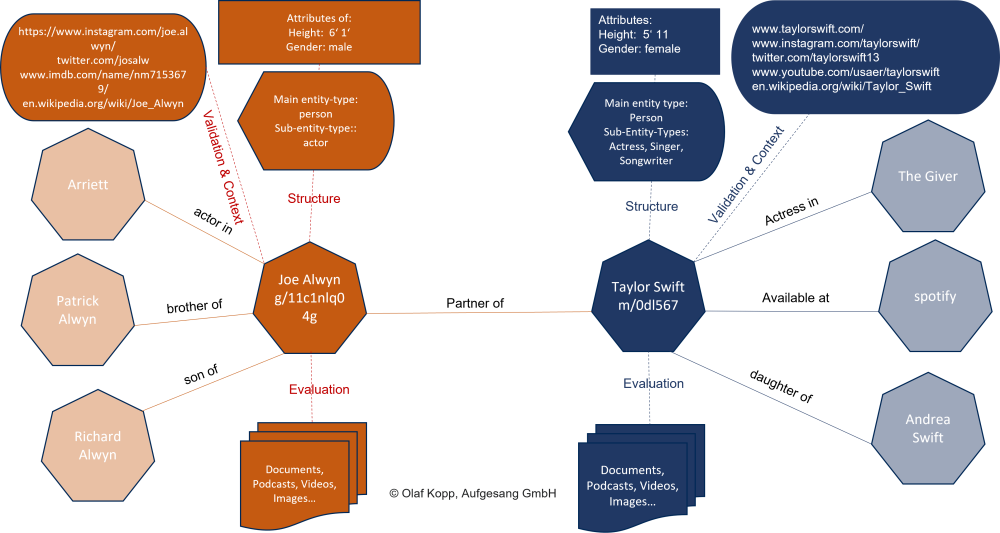
Entities are not just a string of letters but are things with a uniquely identifiable meaning. The search term “jaguar” has several meanings. Thus, the car brand can be meant, the animal or the tank. The mere use of the string in search queries and/or content is not sufficient to understand the context. In combination with other attributes or entities such as rover, coventry, horsepower, car … the unique meaning becomes clear, through the context in which the entity moves. The meaning of entities can be determined by the context in which they are mentioned or used in content and search queries.
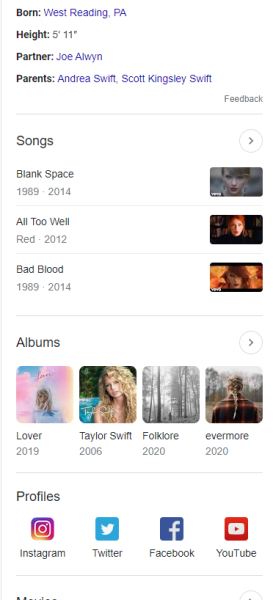
The Knowledge Panel are a like a window for a main entity in the semantic databases of google. But what what information are placed in the knowledge panel are only a small preview of the data google mined and collect around an entity.
Structured and semi-structured data sources for the Knowledge Graph
Google obtains information about entities and their relationships to each other from the following sources:
- CIA World Factbook, Wikipedia / Wikidata (formerly Freebase)
- Google+ and Google My Business, respectively
- Structured data (schema.org)
- Web crawling
- Licensed data
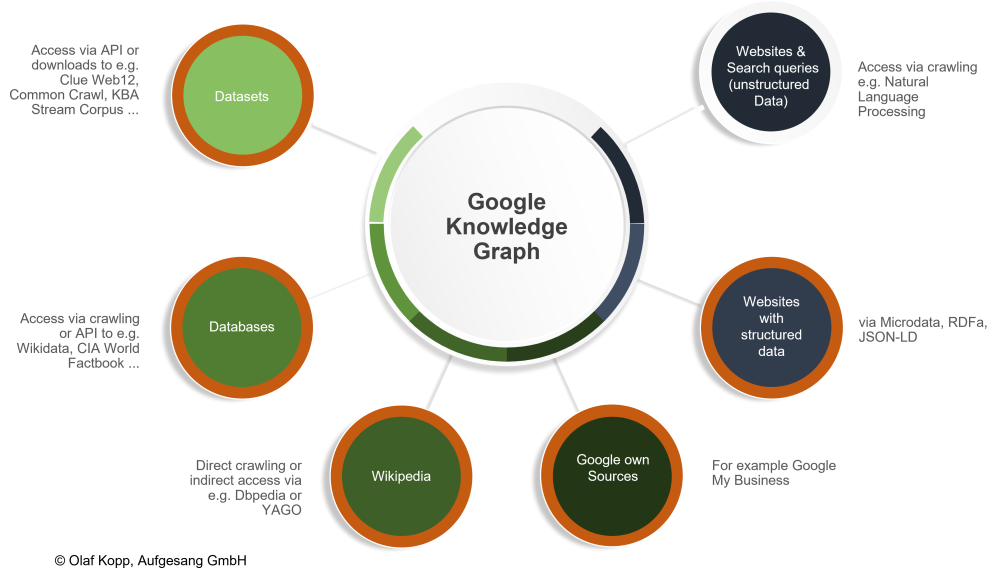
The advantage of manually maintained structured and semi-structured data sources is the validity of the information. The disadvantage is slow scaling. Manually maintained data sources grow very slowly. This makes capturing long tail entities in the Knowledge Graph very slow and would take centuries.
Google needs additional methods to build the Knowledge Graph faster and ensure the validity of the data.
Functionality and application areas of Natural Language Processing in modern search engines
With the launch of BERT in 2018, there was official confirmation from Google that they were using Natural Language Processing for Google Search.
Natural Language Processing as a subarea of Machine Learning is about understanding human language in written and spoken form better and converting unstructured information into machine readable structured data. Subtasks of NLP are translation of languages and answering questions. Here it quickly becomes clear how important this technology is for modern search engines like Google.
In general, the functionality of NLP can be roughly broken down into the following process steps:
- Data provision
- Data preparation
- Text analysis
- Text enrichment
The core components of NLP are tokenization, part-of-speech tagging, lemmatization, dependency parsing, parse labeling, named entity recognition, salience scoring, sentiment analysis, categorization, text classification, extraction of content types, and identification of implicit meaning based on structure.
- Tokenization: Tokenization is the process of dividing a sentence into different terms.
- Word type labeling: Word type labeling classifies words by word types such as subject, object, predicate, adjective …
- Word dependencies: Word dependencies creates relationships between words based on grammar rules. This process also maps “jumps” between words.
- Lemmatization: lemmatization determines whether a word has different forms and normalizes variations to the base form, For example, the base form of animals, animal, or of playful, play.
- Parsing Labels: labeling classifies the dependency or the type of relationship between two words that are connected by a dependency.
- Named Entity Analysis and Extraction: This aspect should be familiar to us from the previous papers. It attempts to identify words with a “known” meaning and assign them to classes of entity types. In general, named entities are people, places, and things (nouns). Entities may also contain product names. These are generally the words that trigger a Knowledge Panel. However, words that do not trigger their own Knowledge Panel can also be entities.
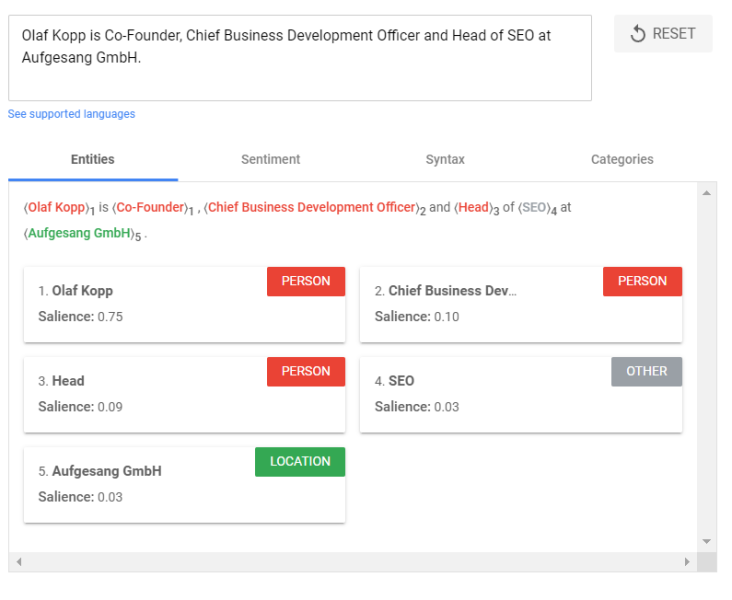
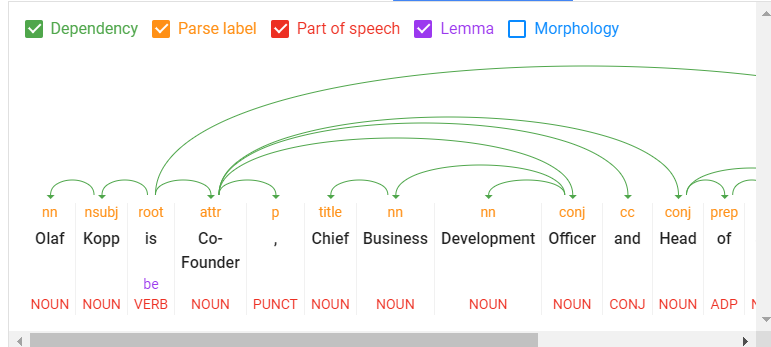
Natural Language Processing can be used to identify entities from search queries, sentences, and text segments, as well as to decompose the individual components into so-called tokens and set them in relation to one another. Even a grammatical understanding can be developed algorithmically by NLP.
With the introduction of Natural Language Processing, Google is also able to interpret more than just nouns for the interpretation of search queries, texts and language. For example, since BERT, verbs, adverbs, adjectives are also important for determining context. By identifying the relationships between tokens, references can be established and thus personal pronouns can also be interpreted.
Example:
“Olaf Kopp is Head of SEO at Aufgesang. He has been involved in online marketing since 2005.”
In the time before Natural Language Processing, Google could not do anything with the personal pronoun “he” because no reference to the entity “Olaf Kopp” could be established. For indexing and ranking, only the terms Olaf Kopp, Head of SEO, Aufgesang, 2005 and Online Marketing were considered.
Natural Language Processing can be used to identify not only entities in search queries and content, but also the relationship between them.
The grammatical sentence structure as well as references within whole paragraphs and texts are taken into account. Nouns or subject and object in a sentence can be identified as potential entities. Through verbs, relationships between entities can be established. Adjectives can be used to identify a sentiment around an entity.
Via Natural Language Processing, concrete W questions can also be better answered, which is a significant advancement for Voice Search operation.
Natural Language Processing also plays a central role for the Passage Ranking introduced by Google in 2021.
Google has been using this technology in Google Search since the introduction of BERT in 2018. The Passage Ranking introduced in 2021 is based on Natural Language Processing, as Google can better interpret individual text passages here thanks to the new possibilities.
Google’s latest innovation, called MUM, represents the next era for Google Search, driven significantly by Natural Language Processing and Natural Language Understanding.
The Knowledge VAULT as possible solution for validation
Before Natural Language Processing Google was dependent on manually maintained structured and semi-structured information or databases, since BERT it has been possible to extract entities and their relationships from unstructured data sources and store them in a graph index. A big step in data mining for the knowledge graph.
For this, Google can use the already verified data from (semi-)structured databases like the Knowledge Graph, Wikipedia … as training data to learn to assign unstructured information to existing models or classes and to recognize new patterns. This is where Natural Language Processing in the form of BERT and MUM plays the crucial role.
Using Natural Language Processing, Google is able to access a huge range of unstructured information from the entire crawlable world wide web. The final major challenge is validating the accuracy of the information. The solution could be a further development of the Knowledge Vault.
As early as 2013, Google recognized that building a semantic database such as the Knowledge Graph based solely on structured data is too slow and not scalable because the large mass of so-called long-tail entities are not captured in (semi-)structured databases. To capture these long-tail entities or the complete knowledge of the world, Google introduced the Knowledge Vault in 2013, but it has not been mentioned much since then. The approach to use the complete knowledge available on the Internet for a semantic database via a technology becomes reality through Natural Language Processing. It can be assumed that, in addition to the Knowledge Graph, there will be a kind of intermediate storage or knowledge repository in which Google will record and structure or organize the knowledge generated via Natural Language Processing. As soon as a validity threshold is reached, the entities and information are transferred to the Knowledge Graph. This intermediate storage could be the Knowledge Vault.
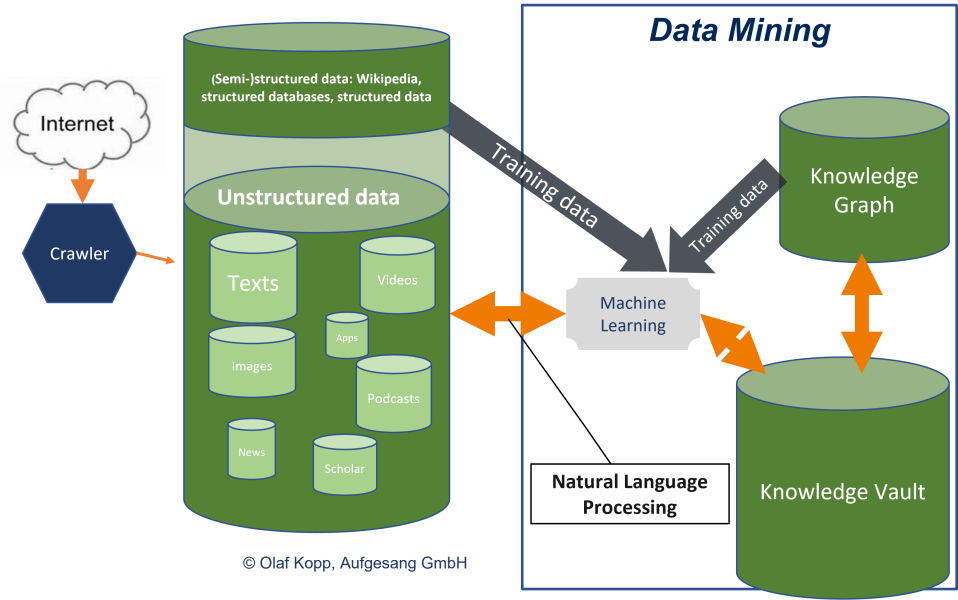
This also explains why the Knowledge Graph has grown very quickly, especially in recent years.
“By mid-2016, Google reported that it held 70 billion facts[4] and answered “roughly one-third” of the 100 billion monthly searches they handled. By May 2020, this had grown to 500 billion facts on 5 billion entities.”, Source: https://en.wikipedia.org/wiki/Google_Knowledge_Graph
And now comes MUM, a technology that is supposed to be even more powerful than BERT. More about this here in the blog in the coming weeks…
- Interesting Google patents for search and SEO in 2024 - 3. April 2024
- What is the Google Shopping Graph and how does it work? - 27. February 2024
- “Google doesn’t like AI content!” Myth or truth? - 19. February 2024
- Most interesting Google Patents for semantic search - 12. February 2024
- How does Google search (ranking) may be working today - 4. February 2024
- Success factors for user centricity in companies - 28. January 2024
- Social media has become one of the most important gatekeepers for content - 28. January 2024
- E-E-A-T: Google ressources, patents and scientific papers - 24. January 2024
- Patents and research papers for deep learning & ranking by Marc Najork - 21. January 2024
- E-E-A-T: More than an introduction to Experience ,Expertise, Authority, Trust - 4. January 2024


Martin Pierags
05.02.2024, 00:50 Uhr
Hallo Olaf, ist die Knowledge Vault dann mit der Webseite verknüpft? Das würde dann ja erklären, warum der Google Cache abgeschafft wird, die wir alle aus den SERPS kennen.
Die Frage, die mich auch beschäftigt ist, wie kann ich all dieses Wissen für mich nutzen? Welche Tools außer dem oben erwähnten “Google Natural Language Processing API” nutzt du?
Beste Grüße
Martin
Olaf Kopp
05.02.2024, 09:27 Uhr
Hallo Martin,
Das Bindeglied zwischen Websites und Google ist immer noch der Crawler. Über ihn werden Texte und Content und im klassischen Suche Index erfasst. Dort kann Google Content wie NLP analysieren, Entitäten identifizieren, extrahieren und mit Attributen versehen, Beziehungen zu anderen Entitäten herstellen sowie weiteren Informationen anreichern. Das Ganze kostet Zeit. Der Knowledge Vault oder so etwas ähnliches ist dann eine Art Knowledge Repository in dem Google Entitäten zwischenspeichert solange bis nahezu sicher ist, dass die Infos vailde sind. Die NLP-API ist für Text-Analyse gedacht.