How does Google process information from Wikipedia for the Knowledge Graph?
The biggest challenge for Google with regard to semantic search is identifying and extracting entities, their attributes and other information from data sources such as websites. The information is mostly not structured and not error-free. The current Knowledge Graph as Google’s semantic center is largely based on the structured content from Wikidata and the semistructured data from Wikipedia or Wikimedia. The article in german >>> Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph?

In the future Google will grow more and more the semantic database(s) via unstructured online content. (more to read in my article NATURAL LANGUAGE PROCESSING TO BUILD A SEMANTIC DATABASE ). In this post, I want to take a closer look at the processing of data from semistructured data sources like Wikipedia.
Contents
- 1 Processing semistructured data
- 2 The processing of semi-structured data using Wikipedia as an example
- 3 How Google can use special pages from Wikipedia
- 4 Databases based on Wikipedia: DBpedia & YAGO
- 5 Categorization of entities based on key attributes
- 6 Collecting attributes with Wikipedia as a starting point
- 7 How is entity information aggregated?
- 8 Information from Wikipedia in Featured Snippets and Knowledge Panels.
- 9 Wikipedia as “Proof of Entity”
- 10 Wikipedia and Wikidata currently (still) the most important data sources
Processing semistructured data
Semistructured data is information that is not explicitly marked up according to general markup standards such as RDF, schema.org … explicitly, but has an implicit structure. From this implicit structure, structured data can usually be obtained via workarounds.
The extraction of information from data sources with semistructured data can be done by a template-based extractor. This can identify content sections based on a recurring same structure of contributions and extract information from them.
The processing of semi-structured data using Wikipedia as an example
Wikipedia or other sources are a very attractive source of information due to the similar structure in each post and constant checking by editors such as Wikipedians. In addition, Wikipedia is based on the MediaWiki CMS. Thus, the contents are provided with rudimentary mark-ups and can be easily downloaded via XML, SQL dumps or as html. One can also speak of semistructured data here.
The structure of a typical Wikipedia article is a template for classifying entities by categories, identifying attributes, and extracting information for featured snippets and knowledge panels. The very similar or identical structure of the individual Wikipedia articles in e.g.
- Title (1)
- Lead Section (2)
- Introduction (2a)
- Infobox (2b)
- Introduction text (2c)
- Table of Contents (3)
- Main text (4)
- Supplements (5)
- Footnotes and sources (5a)
- Related links (5b)
- Categories (5c)
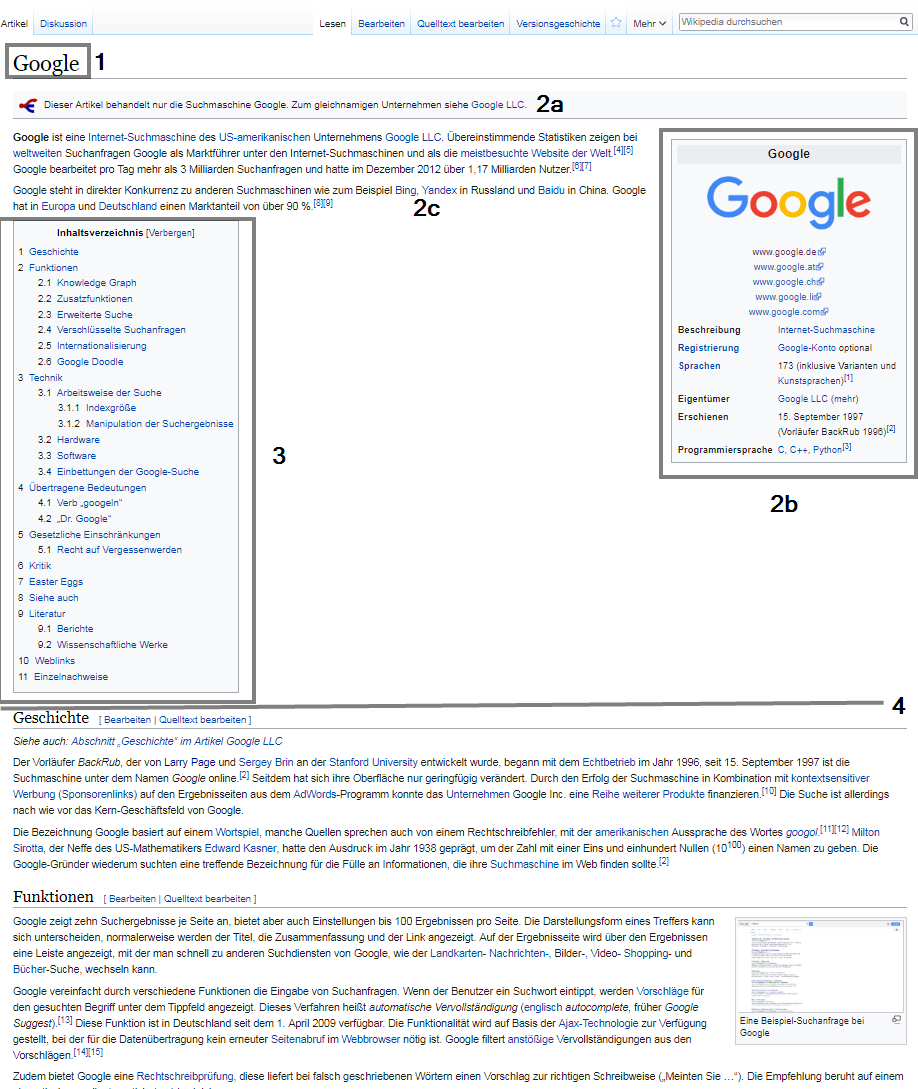
The title of each Wikipedia article reflects the entity name. In the case of ambiguous titles, the entity type is added to the title to distinguish it more clearly from other entities with the same name, as in the case of the football player Michael Jordan. There the title is Michael Jordan (footballer) to distinguish it from the more popular entity of basketball player Michael Jordan.

The info box (2b) at the top right of a Wikipedia article provides structured data about the entity in question. The introductory text (2c) can often be found in the knowledge panel for the respective entity. More about this later in this article.
The internal links within Wikipedia provide Google with information about which further topics or other entities are semantically related to the respective entity.
How Google can use special pages from Wikipedia
Wikipedia offers a number of special pages that can help Google better understand, group, and classify entities.
List & Category pages for classification by entity types and classes.
The categories an entity is assigned to in Wikipedia can always be found at the end of an article (see 5c). On the category pages themselves you will find an overview of all supercategories, subcategories and entities assigned to that category.
List pages (e.g. here ) give an overview of all items related to the list topic, similar to category pages.
Through these two page types, Google could map the respective entity to entity types and classes.
Wikipedia has the most type classes compared to the other major knowledge databases.

The central role that Wikipedia can play in identifying entities and their thematic context is shown in the scientific paper Using Encyclopedic Knowledge for Named Entity Disambiguation.
Relationships between entities could be established by Google via annotations or links within Wikipedia, among other things.
“An annotation is the linking of a mention to an entity. A tag is the annotation of a text with an entity which captures a topic (explicitly mentioned) in the input text.”
Forwarding special pages for the identification of synonyms
Forwarding special pages, such as this one on Online Marketing, direct Wikipedia users to the main term. In this example, Online Marketing is a synonym for the main term Online advertising. Through these redirects, Google can identify synonymous terms for an entity and associate them with the main term.
Term explanation pages for identifying multiple meanings
Term declaration pages like this one for Michael Jordan give an overview of all the entities named Michael Jordan. Here are 5 different entities it applies to. Note that the titles of all 5 entities are worded differently to clearly distinguish them.
This gives Google an overview of which names have ambiguous entities.
Databases based on Wikipedia: DBpedia & YAGO
DBpedia is a multilingual database based on content from Wikipedia or Wikimedia, which is updated regularly. The data is available as linked data for everyone via browser, RDF browser or directly via SPARQL clients. With the module DBpedia Live the database is updated in real time since 2016. Here you can find an example of a DBpedia dataset for the entity Audi A4.

In DBpedia Ontology entities are related to each other or represented as Knowledge Graph. In the following excerpt from DBpedia Ontology entity types (rounded rectangles) are related to parent entity classes via ascending arrows. E.g. the entity types athlete and racer are related to the entity class “person”. Type- and class-associated attributes are shown with the dashed arrows.

The whole thing then represents an ontology that maps the relationships between classes, types and thus entities. The extraction of the data from Wikipedia works via DBpedia Extraction Framework. As sources for the extraction the elements of a Wikipedia article listed above are used.
YAGO is also a semantic database based on the content of Wikipedia. In this database, the focus is more on the creation of entity types and ontologies. For this, YAGO, matches the Wikipedia categories with the hierarchically sorted classes of WordNet. Since the Wikipedia categories do not have a hierarchical structure, YAGO provides additional value in terms of structure.
The elements of DBpedia and YAGO are linked via “same-as-links”. Thus, both databases can be used by Google in parallel without duplicates or redundancies. This way, hundreds of other semantic databases can be used as sources alongside.
YAGO and DBpedia, along with Wikidata, are among the most important structured databases for the Knowledge Graph.
Categorization of entities based on key attributes
In addition to the category and list pages, there are other ways that Google can assign entities to specific entity types and entity classes. For example, the somewhat older Google patent Object categorization for information extraction describes how this can work. The objects described in the patent can be entities.
The patent describes how objects can be assigned to a category or class or type based on identified key attributes. As soon as an object has a threshold of key attributes characteristic for a category, it can be assigned to this category.

E.g. for the entity class “book” an ISBN number, author, publisher and title would be typical key attributes. For an image album, album name, file sizes, image address, dimensions, resolution … characteristic attributes.
This method can be applied to unstructured data as well as to structured data.
Which attributes or which attribute-value pairs are relevant for an entity or entity type could be determined by a methodology described in the Google patent Attribute Value Extraction from Structured Documents.
“In general, one aspect of the subject matter described in this specification can be embodied in methods that include the actions of obtaining an initial attribute whitelist, the initial attribute whitelist including one or more initial attributes; extracting a plurality of candidate attributes from a first collection of documents; grouping the candidate attributes according to both a particular document from which each candidate attribute was extracted and a corresponding structure of that document; calculating a score for each unique attribute in the candidate attributes, where the score reflects a number of groups containing the unique attribute and an attribute on the initial attribute whitelist; generating an expanded attribute whitelist, the expanded attribute whitelist including the initial attributes and each unique attribute having a respective score that satisfies a threshold; and using the expanded attribute whitelist to identify valid attribute-value pairs. “

From now on, further documents can be analyzed that contextually deal with e.g. actors or the entity itself. There, further contextually appropriate attribute-value pairs can be extracted and assigned to the entity in the fact repository. This way, further key-attributes to entity types or classes could also be constantly added.
In addition to an importer module, this is also done via a janitor module, which takes care of duplicate cleansing, data merging, normalization or data cleanliness.
The source for the start research can be Wikipedia articles.
This methodology could also be used to check the correctness of certain values in order to keep the respective database valid.
The first documents mentioned as a source for an initial selection of attributes could be structured data from Wikidata and semi-structured data from Wikipedia.
Collecting attributes with Wikipedia as a starting point
Google’s patent Unsupervised extraction of facts describes a method to continuously collect new facts or attributes of an entity in a fact repository.

This methodology starts with a starting document from which an attribute-value pair or entity type is extracted such as “age (attribute): 43 years (value)” or actor. From the attribute age or type actor, the class human or person can already be derived.
When extracting the seed facts via an importer module from the start document, no qualitative check takes place. That is, the document must be of high quality or correctness. The validity of the collected information depends decisively on the base data. Here, only trustworthy sources of high validity, such as Wikipedia, should be used.
How is entity information aggregated?
The current state of Google still seems to be that, as a rule, all entity information is aggregated from data sources with RDF-compliant structured data and semi-structured data such as Wikipedia.
To gather entity information such as attributes, entity types, entity classes, and relationships to neighboring entities, an entity profile must first be created. This profile is labeled with an entity name and URI as explained in the article What is an entity ? before, which allows a unique assignment.
This profile is then supplied with information about this entity from various data sources. Here is an example of how something like this might look for the Audi A4 entity:

In this example, the information comes from Wikipedia or DBpedia and the entity is linked to the same entity at Freebase.
Information from Wikipedia in Featured Snippets and Knowledge Panels.
Especially with the increasing importance of spoken search queries or voice search, modern search engines try to provide answers immediately without the user having to navigate through 10 blue links on the first search results page. To do this, the meaning of the search term must be identified and, secondly, relevant information must be extracted from structured and unstructured data sources. The solution for this is Entity Retrieval.
The task of entity retrieval is to identify relevant entities from a catalog in response to a written or spoken search query and to output them sorted by relevance to the search query in a list. To output an answer, an excerpt is required that briefly and concisely explains the entity.
We know this kind of description from the Featured Snippets as well as from the entity descriptions in the Knowledge Panels, which are mostly extracted from Wikipedia or DBpedia. In the Featured Snippets, information is also extracted from unstructured sources such as magazines, glossaries or blogs. However, Google currently seems to use descriptions from unstructured sources only as a stopgap solution and prefers descriptions from Wikipedia.
Google currently trusts the information from Wikipedia the most to populate Featured Snippets. There can be several reasons for this. On the one hand, it is easy to extract the introductory text of an article due to the clear structure of Wikipedia. This describes the topic briefly and concisely.
How exactly Google extracts information from unstructured website texts for the Featured Snippets is speculation. The guesses are many and varied. I believe that it is primarily related to triples of object, predicate and subject occurring in the paragraph. But more about that in the next post in my series of posts.
The frequency of Wikipedia information in the Featured Snippets leads to the assumption that Google is not yet satisfied with the results of the extraction of unstructured data and/or has not yet gotten the manipulation attempts under control.
Wikipedia as “Proof of Entity”
The surest way to be perceived as an entity is an entry at Wikipedia, Wikidata or the submission to Google itself.
But Google reserves the right to check the entries and delete them from the databases if you do not provide enough referencing sources in the Wikidata entry. To prevent manipulation, an entry must be verified from at least one third source. At least that’s how it seems. A Wikipedia page or Wikimedia entry seems to be an important source here.
While in Wikidata attributes of an entity are assigned rather stichpunkartig Wikipedia describes the entity in a detailed text. A Wikipedia entry is thus the detailed description of an entity and, as an external document, represents an important source for the Knowledge Graph.
For example, a unique identification reference may be stored within the node, a short information string may be stored in a terminal node as a literal, and a long description of an entity may be stored in an external document linked to by a reference in the knowledge graph. Quelle: “https://patents.google.com/patent/US20140046934A1/en”
In a scientific project in which a Google employee was also involved, an entity is equated with a Wikipedia article.
“An entity (or concept, topic) is a Wikipedia article which is uniquely identified by its page-ID.”
Wikipedia entries play a predominant role in many Knowledge Graph boxes as a source of information and are used by Google alongside Wikidata entries as proof of the relevance of an entity. Without an entry at Wikipedia or Wikidata, there is no entity box or knowledge panel.
However, an entry at Wikipedia is denied to most companies and individuals, as they lack social relevance in the eyes of Wikipedians.
A useful alternative is to set up a profile at Wikidata. The frequency of recurring consistent data across different trusted sources makes it easier for Google to clearly identify entities.
Wikipedia and Wikidata currently (still) the most important data sources
For more than 10 years, Google has been striving to make a knowledge database like the current Knowledge Graph bigger and bigger. This is shown by the countless patents. The entire net community also shows a great interest in archiving human knowledge, networking it and mapping it as completely as possible, as shown by the many knowledge databases maintained mostly by volunteers. These databases are now what humanity used to collect and maintain in vast libraries.
And Google wants to be the number one gatekeeper to this knowledge.
But there is still a long way to go, especially in terms of completeness. Databases and portals like Wikidata and Wikipedia have evolved into enormous knowledge databases of structured and semi-structured data. Services like DBpedia and YAGO provide a kind of interface for Google and other processing entities.
Wikipedia, as a base, represents a very good accessible and trustworthy knowledge database around entities.
The big disadvantage is that only a fraction of all named entities and concepts are described in Wikipedia and Wikidata.
In order to get an overview of all entities, concepts and topics, these databases, which are largely maintained manually by humans, are not sufficient as a basis.
The goal must be to capture the entire knowledge represented on the Internet. With this goal one is in the area of conflict between validity and completeness. In addition, manipulation must be stopped.
Technical procedures must be developed that take these points into account. Here, there is no way around the automated processing of unstructured data sources. This is another reason why Google is pushing ahead with its commitment to machine learning.
That’s why my next post will be about the processing of unstructured data.
I hope this post could help you regarding semistructured data, Wikipedia in terms of entities and the Knowledge Graph. Spread the Word!
German article >>> https://www.sem-deutschland.de/blog/google-informationen-wikipedia/
- Interesting Google patents for search and SEO in 2024 - 3. April 2024
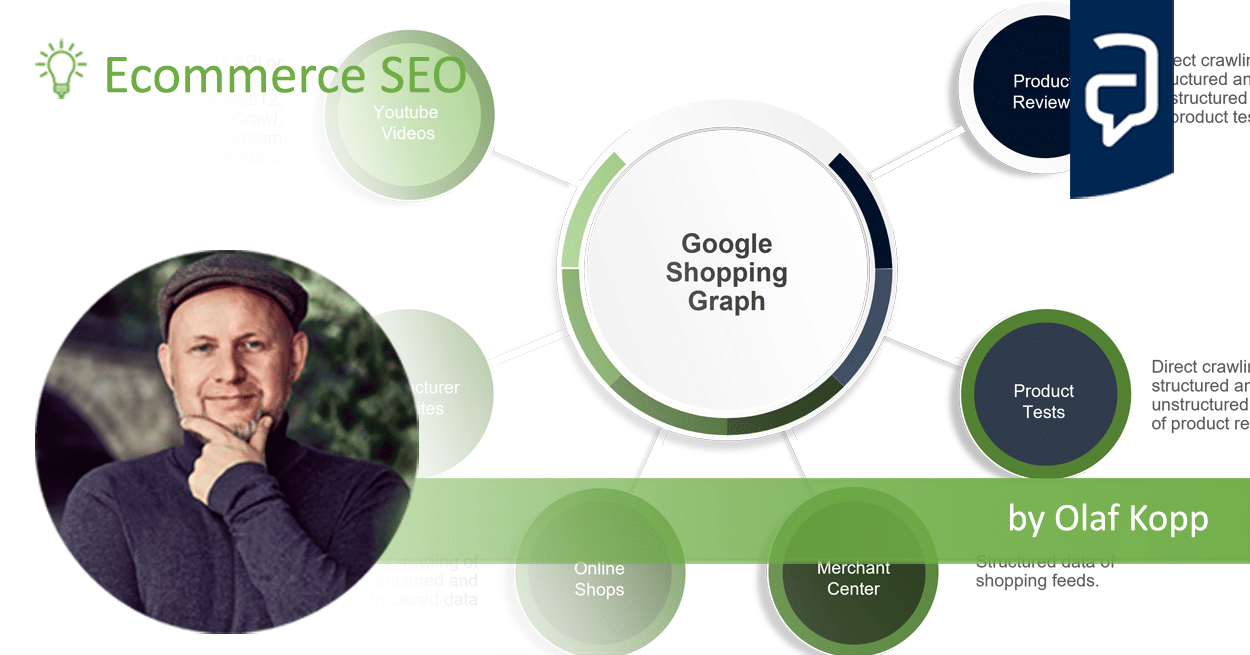
- What is the Google Shopping Graph and how does it work? - 27. February 2024
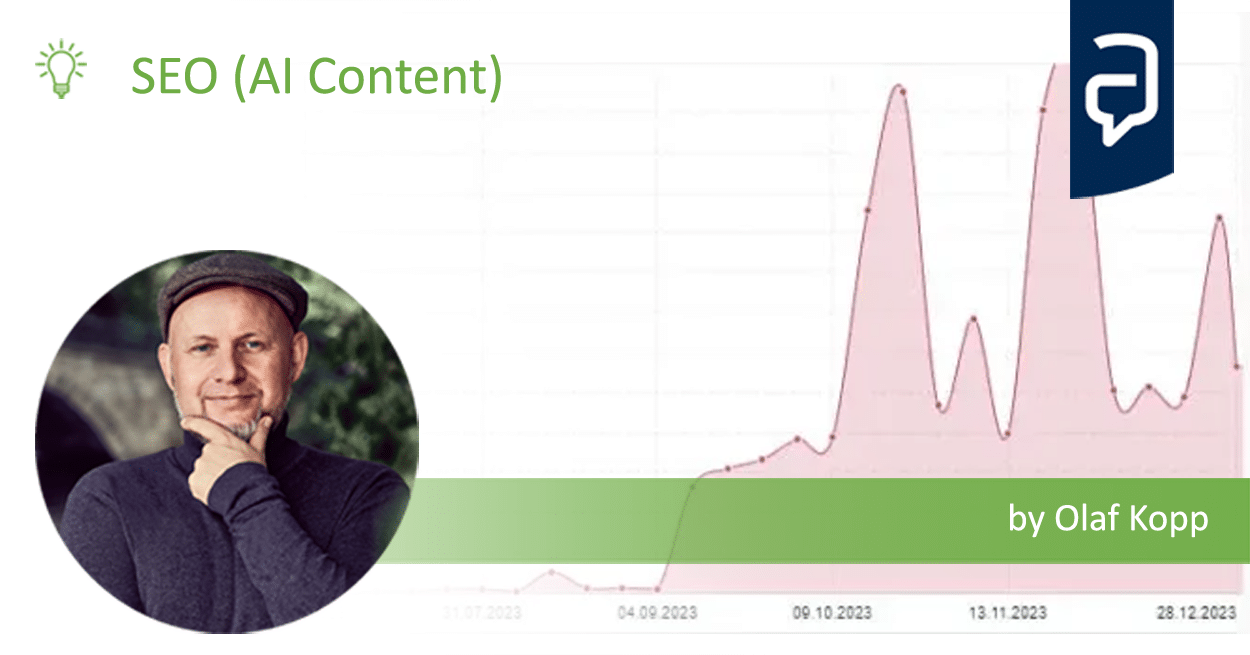
- “Google doesn’t like AI content!” Myth or truth? - 19. February 2024
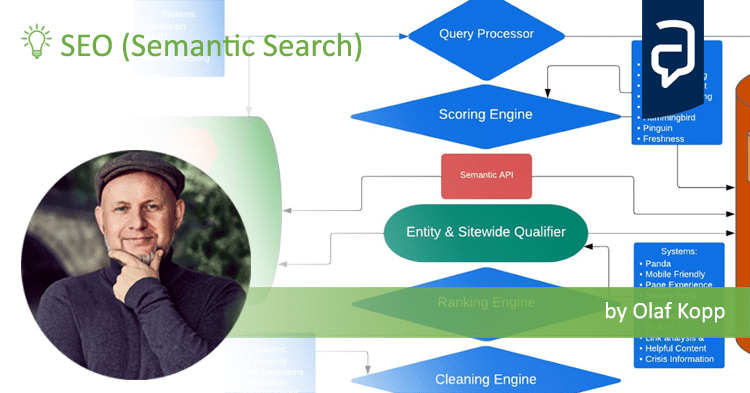
- Most interesting Google Patents for semantic search - 12. February 2024
- How does Google search (ranking) may be working today - 4. February 2024
- Success factors for user centricity in companies - 28. January 2024
- Social media has become one of the most important gatekeepers for content - 28. January 2024
- E-E-A-T: Google ressources, patents and scientific papers - 24. January 2024
- Patents and research papers for deep learning & ranking by Marc Najork - 21. January 2024
- E-E-A-T: More than an introduction to Experience ,Expertise, Authority, Trust - 4. January 2024