How can Google identify and rank relevant documents via entities, NLP & vector space analysis?
This article deals with how Google identifies and ranks appropriate content for entity-related search queries using Natural Language Processing and vector space analysis, among other things. I have worked through various Google patents and other sources (List at the end of the article) and summarized the extract below. German article >>> https://www.sem-deutschland.de/blog/entitaeten-relevanzbestimmung/
Contents
- 1 The role of entities in search
- 2 The role of relevance at Google
- 3 Determining the relevance of documents via Natural Language Processing
- 4 Determining the relevance of documents using vector space analyses
- 5 Identification of entity-relevant documents
- 6 Entity-based scoring of documents
- 7 Entities, Natural Language Processing, and Vector Space Analysis as Key Approaches for Indexing and Ranking.
- 8 Google patents for determining the relevance of content using entities
The role of entities in search
To keep the overview I would like to start by summarizing the possible tasks of entities in information retrieval systems like Google. The following tasks are necessary for an information retrieval system based on entities:
- Interpretation of search queries
- Relevance determination on document level
- Evaluation on domain level / publisher
Output of an ad-hoc response in the form of a search results, knowledge panels, featured snippets …
In all these tasks, the interplay of entities, search queries and relevance of the content must be fulfilled.This article focuses on determining the relevance of a document with respect to the entities and/or search terms identified in a search query.
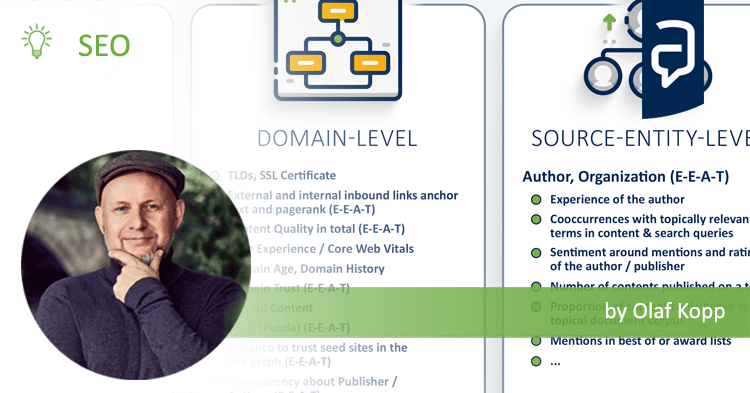
You can read more on the evaluation on domain ord publisher level in my article Entities and E-A-T: The role of entities in authority and trust on Search Engine Land.
The role of relevance at Google
We have to differentiate between relevance (objective relevance), pertinence (subjective relevance) and usefulness (situational relevance). In this article, I will focus only on the objective relevance of a document, since pertinence and usefulness have more to do with personalization.
Relevance determination takes place in two steps. First, a document corpus of n documents has to be determined with respect to a search query. This is usually done using very simple information retrieval processes. Here, the occurrence of the search term or of synonyms in the document plays a role. Thereupon, these documents can also be provided with annotations or comments similar to tags in order to classify them by topic. Theoretically, these could also be annotated with further tags, such as by purpose (sell, advise, inform…). However, this process most likely already happens when parsing the content. The document is then ready annotated in the index.
When a search query is triggered, the search engine accesses the appropriate corpus of documents including comments. The interpretation of the search query or the search intention plays a decisive role.
In the second step, a ranking engine such as the Hummingbird algorithm uses scoring to determine how relevant the document in question is to the search query. Besides the relevance determination, Google will apply further scoring levels on quality level regarding e.g. core web vitals, timeliness or trustworthiness (Trust) as well as authority of the source and expertise (E-A-T) to determine a ranking. Which of these scoring types are then weighted and how heavily will likely vary individually by industry or even keyword. This scoring is only done for the first 30-50 most relevant search results in real time for the benefit of computational speed.
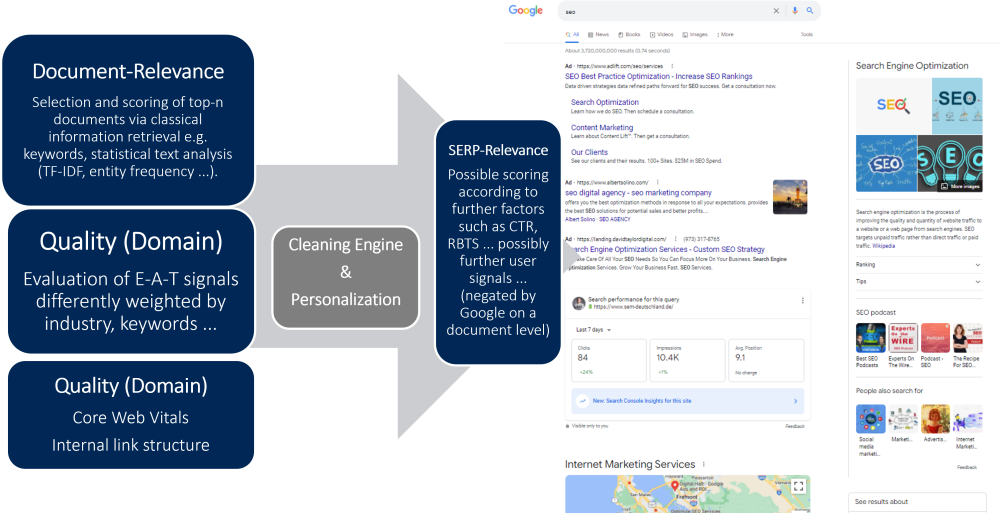
There are two main methods used in relevance determination for a document.
- Natural Language Processing
- Vector Space Analyses
In this post I will focus on relevance scoring at the document level. So not with quality scoring. For that, check out my posts on E-A-T here in the blog or at Search Engine Land.
Determining the relevance of documents via Natural Language Processing
That Google already uses NLP in many areas of search can be guessed from the introduction of the BERT / MUM update and Google’s Natural Language Processing API. The BERT update refers to the interpretation of search queries. Therefore, I will not go into more detail at this point.
In the end it doesn’t matter if you apply NLP to a search term or a text or a text fragment like a paragraph, sentence or word string. The process is the same.
- Tokenization: Tokenization is the process of dividing a sentence or text fragment into different terms.
- Labeling words by word types: Word type labeling classifies words by word types such as subject, object, predicate, adjective …
- Word dependencies: Word dependencies creates relationships between words based on grammar rules. This process also maps “jumps” between words.

- Lemmatization: Lemmatization determines whether a word has different forms and normalizes variations to the base form. For example, the base form of animals, animal, or of playful, play.
- Parsing Labels: labeling classifies the dependency or the type of relationship between two words that are connected by a dependency.
- Named Entity Analysis and Extraction: This aspect should be familiar to us from the previous papers. It attempts to identify words with a “known” meaning and assign them to classes of entity types. In general, named entities are people, places, and things (nouns). Entities may also contain product names. These are generally the words that trigger a Knowledge Panel. However, words that do not trigger their own Knowledge Panel can also be entities.
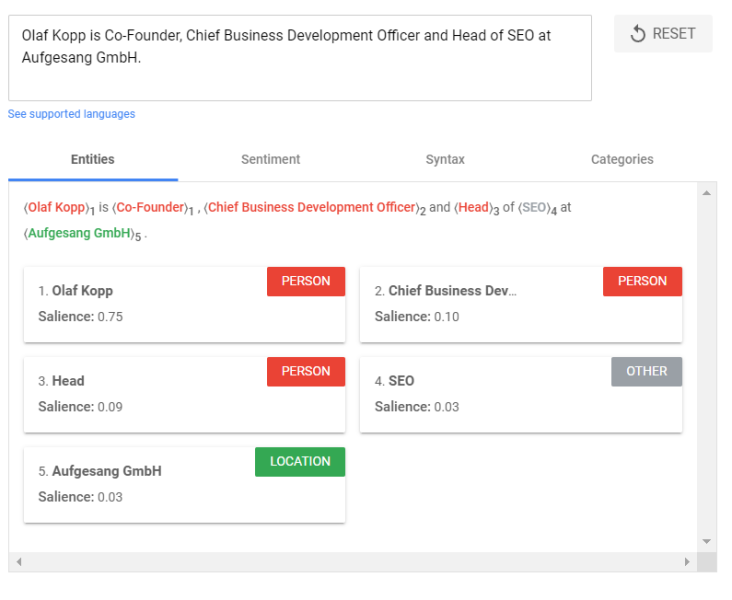
- Salience scoring: Salience determines how intensively a text deals with a topic. This is determined in NLP based on what are called indicator words. In general, salience is determined by the co-citation of words on the web and the relationships between entities in databases such as Wikipedia and Freebase. Google likely applies this linkage diagram to entity extraction in documents to determine these word relationships. A similar approach is familiar to experienced SEOs from TF-IDF analysis.
- Sentiment analysis: In short, this is an assessment of the opinion (view or attitude) expressed in an article about the entities covered in the text.
- Subject categorization: At the macro level, NLP classifies text into subject categories. Subject categorization helps to generally determine what the text is about.
- Text classification & function: NLP can go further and determine the intended function or purpose of the content.
- Content Type Extraction: Google can use structural patterns, or context, to determine the content type of a given text without exposition with structured data. The HTML, formatting of the text, and the data type of the text (date, location, URL, etc.) can be used to understand the text without additional markup. Using this process, Google can determine whether text is an event, recipe, product, or other content type without using markup.
- Identify implicit meaning based on structure: The formatting of a body of text can change its implicit meaning. Headings, line breaks, lists, and proximity convey a secondary understanding of the text. For example, when text is displayed in an HTML-sorted list or in a series of headings with numbers in front of them, it is likely to be an operation or a ranking. Structure is defined not only by HTML tags, but also by visual font size/thickness and proximity during rendering.
Natural Language Processing plays a large role in pre-classification and annotation of text accordingly. Wine look at the documentation of Google’s Natural Language Processing API shows that texts can be classified into content categories via the API. This could then be used to compile document corpuses for the index.
You can find a complete list of all content categories here.
Entity analysis can be used to determine the main and secondary entities of a document, and the salience score can be used to rank the secondary entities.
Entity analysis returns a set of detected entities and the parameters associated with those entities, such as entity type, relevance of the entity to the overall text, and text passages that refer to the same entity. Entities are returned in order of their salience scores (from highest to lowest), which reflect their relevance to the overall text.
The salience score is a weighting within the text or text fragment. It cannot be used for an evaluation of the document within the respective corpus i.e. for scoring with respect to ranking.
You can test the functionality of Google’s NLP API yourself here via the demo.
In summary, NLP can be used primarily for understanding, classifying and organizing texts/documents/content. Entities will play a more and more central role in the organization.
Determining the relevance of documents using vector space analyses
To determine the relevance of documents in relation to a search query, Google uses so-called vector space analyses, which map the search query as a vector and relate it to relevant documents in the vector space. If known entities already occur in the search term, Google can then relate this to documents in which these entities are also named. Documents can be any kind of content like text, images, videos …
The size of the angle of the vectors can be used to score the documents. It could also be the click behavior in the SERPs that plays a role in determining relevance.
Vectors and vector spaces can be applied at different levels. Whether it is Word2Vec, Phrase2Vec, Text2Vec or Entity2Vec. The main vector represents the central element. If it is an entity, it can be placed in relation to other entities or documents.


Vector space analyses can be used for scoring with regard to ranking, but can also simply be used for the organization of elements such as semantically close entities, topics or topic-specific terms. If the main vector is a search term related to documents, the size of the angle or proximity can be used for ranking or scoring.
Identification of entity-relevant documents
The identification of documents that are relevant for a requested entity can be done by annotating or tagging the relevant documents or by identifying entity mentions. This can be done manually by editors or automated.
Thus, authors or editors can tag contributions with tags for all named entities occurring in the text, such as people, places, organizations, products, events … and concepts. This would create a relevant corpus of documents per entity. However, via this method alone, it is not possible to weight the documents with respect to the entity. There is only tagged or not tagged.
In the case of Google, one can assume an automated process due to the large number of documents, as described in the section on Natural Language Processing.
Furthermore, it is possible that Google documents are weighted based on the frequency of entity mentions, similar to term frequency. Documents that exceed a certain threshold of a term or entity frequency are included in the scoring process. The rest remain unweighted and are ranked rather randomly from position 30-50 onwards.
The analysis of the frequency of occurring terms is not a new invention and should not be foreign to any SEO.
Similar to the inverse term frequency TF-IDF or WDF*IDF, an inverse entity frequency can be determined. Here, the number of terms and other entities occurring in an entity description are put into relation and these are then put into relation to all entity-relevant documents in the corpus.
Using the entity-relevant documents, connections between terms and entities can be determined in the first step. The more frequently a co-occurrence occurs between certain terms and an entity, the more likely a relation to each other is. While in TF-IDF the proof terms are determined by the relation to a keyword, here the terms are determined in relation to the requested entity.
The weighting is additionally done by the relevance of the respective document in which the co-occurrence occurred. In other words, the proximity of the document to the queried entity.
The formula for this is as follows:

Here t stands for term, e for entity, d for document.
The terms that occur in the immediate vicinity of the named entities as co-occurrences can be linked to this entity. From this, attributes as well as other “secondary entities” to the “main entity” can be extracted from the content and stored in the respective “entity profile”. The proximity between the terms and the entity in the text as well as the frequency of the occurring main entity-attribute pairs or main entity-subsidiary entity pairs can be used as validation as well as weighting.
A similar approach has been used by Google officially confirmed for a long time in the evaluation of links. Here, the focus is not only on the anchor text of the link, but also on the surrounding terms.
Here the two procedures Bag of Words and Contextual Bag of Words (CBOW) should not remain unmentioned.
It is not possible to make a general statement about the number of words or the size of a window for a text fragment. Theoretically, it could also be an entire text. However, it makes more sense to look at individual paragraphs or chapters in combination with an overall view of a text. This would also explain why very extensive content for hundreds of terms together can have top rankings.
Entity-based scoring of documents
The scoring of documents with respect to an entity-relevant search query proceeds in two steps. First, a selection of top-n documents is determined and ranked according to classical information retrieval approaches. In the second step, the relevance of these documents with respect to the queried entity(ies) is weighted and the order is reordered. Here is the formula for doing this:

Where e stands for entity, q for query, d for document, and Dq for all documents that are at all relevant to the query. The performance can be improved significantly if Dq is limited to the top k documents only.
Entity-based scoring can be performed using the same scoring algorithms as term-based search systems except that terms are swapped for entities. To improve performance, it would still be possible to store the associated entities and their weights per document in the document index.
This type of entity-based scoring can be easily superimposed on a classic keyword-based search, or both methods can be used on their own or in combination.
Entities, Natural Language Processing, and Vector Space Analysis as Key Approaches for Indexing and Ranking.
To conclude this post, I would like to draw an interim conclusion from my findings over the last 10 months of research.
Advances in machine learning and quantum computing are making methods like Natural Language Processing and vector space analysis increasingly performant and scalable for Google to use in practice, making entity, query, and content interpretation and ranking increasingly feasible.
I’ve been looking at the possible data sources for the Knowledge Graph and the challenges Google faces in data mining information for the Knowledge Graph. In the process, it has become clear which central role Natural Language Processing has for data mining from unstructured data for Google. However, the tension between completeness and accuracy of the information remains.
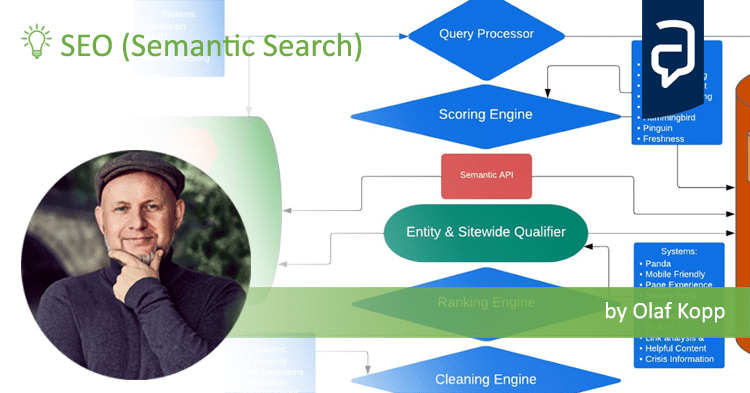
The diagram I developed on the possible information process at Google seems to come close to the whole thing.

The interpretation of the search terms is handled by Rankbrain with respect to search intention and BERT / MUM with respect to semantic thematic classification of the search query. Both NLP (MUM / BERT) and vector space analysis (Rankbrain) are used. It is also decisive to what extent the search query has an entity reference or not. This determines how big the influence of the information from the Knowledge Graph is.
Entities are increasingly becoming the central organizational element in the Google index. Insofar as search queries have an entity reference, Google can quickly access all stored information about the relevant entities and relationships to other entities via the Knowledge Graph. Search queries without reference to entities recorded in the Knowledge Graph are handled as usual according to classic information retrieval rules. However, Google can now use NLP to identify entities that are not in the Knowledge Graph, provided that the search term contains an existing grammatical structure of subject, predicate and object (triples).
I think that in the future there will be an increasing exchange between the classic Google search index and the Knowledge Graph via an interface. The more entities are recorded in the Knowledge Graph, the greater the influence on the SERPs. However, as mentioned in other posts in this series, Google still faces the major challenge of reconciling completeness and accuracy. More about Data Mining via Natural Language Processing in my article NATURAL LANGUAGE PROCESSING TO BUILD A SEMANTIC DATABASE .
For the actual scoring by Hummingbird, the document-level entities do not play a major role. They are rather an important organizational element for building unweighted document corpuses on the search index side. The actual scoring of the documents is done by Hummingbird according to classical information retrieval rules. However, on domain level I see the influence of entities on ranking much higher. Keyword: E-A-T.
Google patents for determining the relevance of content using entities
In the following, I would like to conclude with a few Google patents that particularly caught my eye during the research and support the approaches described above. All patents listed are still active, have a term until at least 2025 and are subscribed by Google.
-
Ranking search results based on entity metrics
-
Identifying topical entities
-
Question answering using entity references in unstructured data
-
Selecting content using entity properties
-
Automatic discovery of new entities using graph reconciliation
-
Systems and methods for re-ranking ranked search results
-
Document ranking based on entity frequency
-
Additive context model for entity resolution
-
Document ranking based on semantic distance between terms in a document
-
Mapping images to search queries
- The dimensions of the Google ranking - 25. April 2024
- Interesting Google patents for search and SEO in 2024 - 3. April 2024
- What is the Google Shopping Graph and how does it work? - 27. February 2024
- “Google doesn’t like AI content!” Myth or truth? - 19. February 2024
- Most interesting Google Patents for semantic search - 12. February 2024
- How does Google search (ranking) may be working today - 4. February 2024
- Success factors for user centricity in companies - 28. January 2024
- Social media has become one of the most important gatekeepers for content - 28. January 2024
- E-E-A-T: Google ressources, patents and scientific papers - 24. January 2024
- Patents and research papers for deep learning & ranking by Marc Najork - 21. January 2024