E-E-A-T: Google ressources, patents and scientific papers
E-E-A-T has become one of the most important ranking influences for Google search results since 2018 due to the Core updates and will gain additional importance with the introduction of SGE. In this post, I’d like to give a list and introduction to the most interest Google patents and papers regarding E-E-A-T. Please share the knowledge!
More about Google patents in my followings arcticles:
- Most interesting Google Patents for semantic search
- Most interesting Google patents and research papers for ranking by Marc Najork
- Most interesting Google Patents for SEO in 2023
Contents
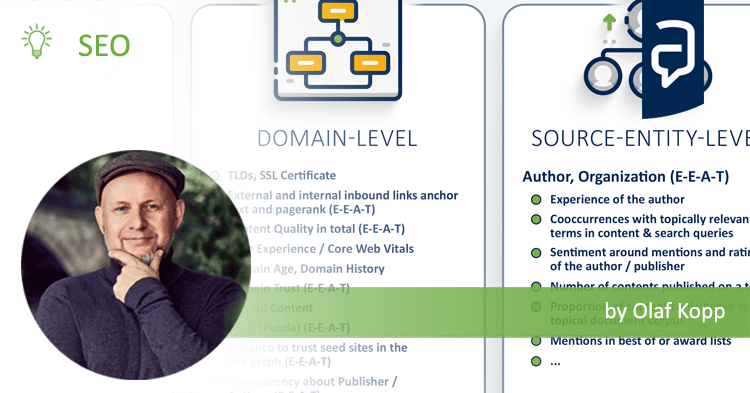
- 1 Overview: Possible factors influencing E-E-A-T
- 2 Resource scoring adjustment based on entity selections
- 3 Scoring site quality
- 4 Classifying sites as low quality sites
- 5 Determining a quality measure for a resource
- 6 Site quality score
- 7 Identifying navigational resources for informational queries
- 8 Ranking Search Results Based on Entity Metrics
- 9 Obtaining authoritative search results
- 10 Producing a ranking for pages using distances in a web-link graph
- 11 Combating Web Spam with Trust Rank
- 12 Search result ranking based on trust
- 13 Credibility of an author of online content
- 14 Sentiment detection as a ranking signal for reviewable entities
- 15 Systems and Methods for Re-Ranking ranked Search Results
- 16 Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources
- 17 Website Representation Vector
- 18 Generating author vectors
- 19 How Google fights Disinformation
- 20 Search Quality Evaluator Guidelines
- 21 Google documentation on Panda
- 22 Google on Creating helpful, reliable, people-first content
- 23 Google on Understanding news topic authority
Overview: Possible factors influencing E-E-A-T
Based on the following resources, our own experience and further statements from Google, we have created the following overview of possible measurable factors for an E-E-A-T evaluation. Please share the knowledge!

Resource scoring adjustment based on entity selections
Patent ID: US10303684B1
Countries Published For: United States
Last Publishing Date: May 28, 2019
Expiration Date: May 6, 2037
Inventors: Kenichi Kurihara
The Patent addresses the challenges and mechanisms involved in digital information retrieval, particularly in the context of search engines.
The ranking process involves scoring resources using factors such as information retrieval scores, which measure the relevance of a query to the content of a resource, and authority scores, which assess the importance of a resource relative to others.
Moreover, the background highlights the use of additional factors, including user feedback, to adjust resource scores. Resources that frequently satisfy users’ informational needs for specific queries are selected more often, indicating their relevance and utility. This user selection data allows search engines to adjust search scores, giving a “boost” to resources that perform well in satisfying users’ needs. However, the document also notes the challenge of scoring resources with insufficient search and selection data, such as newly published resources, which may not have a history of user interactions to inform their relevance and ranking.
Claims
Accessing Resource Data: The system accesses data specifying a plurality of resources. For each resource, this data includes a unique identifier and information on one or more entities referenced within the resource.
Accessing resource data involves the search engine’s system collecting and using information about various online resources, such as websites, articles, or videos. Each resource is identified by a unique code or identifier, making it distinguishable from others. Additionally, the system identifies and records the specific topics, concepts, or entities (like places, people, or things) that each resource mentions or discusses.
In simpler terms, imagine the search engine going through a library of digital content and taking notes on what each piece of content is about and what specific subjects it covers. This process helps the search engine understand the content and context of each resource, preparing it for more detailed analysis, such as figuring out how relevant a resource is to certain search queries based on the entities it references.
Accessing Search Term Data: It also accesses data specifying a set of search terms. For each search term, there is a selection value for each resource, which is determined based on user selections of search results that referenced the resource.
Accessing search term data refers to the process where the search engine collects and analyzes information about the words or phrases (search terms) that people use when they look for information online. For each search term, the system also gathers data on how users interact with the search results—specifically, which results they choose to click on or select. This interaction is measured through selection values assigned to each resource, indicating its relevance or attractiveness to users based on the search term used.
To put it simply, imagine the search engine keeping track of what people are searching for and noticing which websites or pages they end up visiting from the list of results it provides. This helps the search engine understand which resources are more useful or relevant to users for specific search terms, guiding it in improving how it ranks and presents search results in the future.
Determining Search Term-Entity Selection Values: From the resource and search term data, the system calculates a search term-entity selection value for each search term and each entity. This value is based on the selection values of resources that reference the entity and were included in search results for queries containing the search term.
Determining search term-entity selection values involves a sophisticated process where the search engine calculates specific values that represent how often users select resources based on the entities those resources reference in relation to specific search terms. This process is a key part of the patent and involves several steps:
- Combining Resource and Search Term Data: The system first looks at the information it has gathered about resources (such as web pages or articles) and the entities (topics, concepts, or things) they mention. It also considers the search terms people use and how they interact with the search results related to these terms.
- Analyzing User Selections: For each combination of a search term and an entity, the system analyzes how frequently resources mentioning that entity are selected when they appear in search results for that search term. This involves looking at the selection values for resources, which are based on user clicks or interactions.
- Calculating Selection Values: Based on this analysis, the system calculates a “search term-entity selection value.” This value reflects the likelihood of resources referencing a particular entity being selected in response to a specific search term. It’s a measure of the relevance and appeal of resources related to certain entities for specific search queries.
In simpler terms, this process is like figuring out how popular certain topics are among people searching for specific things. For example, if many people search for “healthy recipes” and often choose articles that mention “quinoa,” the search term-entity selection value for “quinoa” in relation to “healthy recipes” would be high. This indicates that quinoa is a relevant and appealing topic for people interested in healthy recipes.
This calculated value helps the search engine understand which topics or entities are most relevant to users’ interests based on their search behavior. It can then use this information to adjust how it ranks and presents search results, aiming to show users the most relevant and useful information first.
Storing Search Term-Entity Selection Values: Finally, the system stores these calculated search term-entity selection values in a data storage.
- Data Storage: The search engine uses a data storage system, which could be databases or other forms of digital storage, to keep the calculated search term-entity selection values. This storage allows the system to quickly access these values when needed, without having to recalculate them each time.
- Organized and Efficient Access: The values are stored in an organized manner, ensuring that the search engine can efficiently retrieve them when processing search queries. This organization might involve indexing the values based on search terms, entities, or other relevant criteria to speed up access.
- Use in Ranking Process: When a new search query is entered, the search engine can pull the relevant search term-entity selection values from storage to help determine the ranking of resources in the search results. This means that if a particular entity is highly relevant to a search term based on past user selections, resources referencing that entity can be ranked higher.
Implications for SEO
1. Entity-Based Optimization:
SEO strategies need to evolve beyond traditional keyword optimization to include entity-based optimization. This means creating content that not only targets specific keywords but also thoroughly covers related entities (people, places, things, concepts) that users might associate with these keywords. Understanding and incorporating relevant entities into content can increase its visibility and ranking in search results.
2. User Intent and Behavior:
The patent highlights the importance of aligning content with user intent and behavior. SEO practitioners must analyze how users interact with content related to specific search terms and entities. This involves understanding which types of content users prefer and how they select resources in search results. Optimizing content to meet user expectations and satisfy their informational needs can lead to better engagement and higher selection values, potentially boosting search rankings.
3. Quality and Relevance of Content:
The mechanism described in the patent suggests that Google could use selection values as a signal of content quality and relevance. Therefore, producing high-quality, relevant content that addresses the needs and interests of the target audience is crucial. Content that effectively engages users and matches their search intent is more likely to be selected, positively influencing its search term-entity selection values and, by extension, its search rankings.
4. Data-Driven SEO Strategies:
SEO strategies should become more data-driven, with an emphasis on analyzing user behavior data to inform content creation and optimization. This includes studying which entities are frequently associated with high selection values for specific search terms and understanding the context in which these entities are discussed. Leveraging analytics tools to gather insights into user preferences and content performance will be key.
5. Long-Tail and Semantic Search Optimization:
Given the focus on entities and their relation to search terms, optimizing for long-tail keywords and semantic search becomes increasingly important. Long-tail keywords, which are often more specific and query-like, can capture the user’s intent more accurately and may include relevant entities directly. Semantic search optimization involves structuring content to answer questions and cover topics comprehensively, reflecting the natural way people search for information.
Scoring site quality
- Patent ID: US9195944B1
- Countries Published For: United States
- Last Publishing Date: November 24, 2015
- Expiration Date: October 19, 2033
- Inventors: Vladimir Ofitserov
- Current Assignee: Google LLC
The patent emphasizes the importance of accurately assessing the quality of sites to improve the relevance and usefulness of search results presented to users. This involves developing methods to score the quality of sites based on user interaction metrics, such as the duration of visits to the site’s resources, independent of the specific queries submitted by users.

Claims
Obtaining Measurements: Collecting a plurality of measurements related to the durations of user visits to resources within a specific site. These measurements can come from various sources, including direct user interactions (e.g., time spent on a page after clicking a search result) and data from network monitoring systems or server logs.
Computing the Site Quality Score: The site quality score is calculated using these measurements, specifically by computing a statistical measure (such as mean, median, or mode) from the collected data. This score aims to represent a query-independent measure of the site’s usefulness in providing information that meets the informational needs of its visitors.
- Measurements of User Visit Durations: The core signal involves collecting data on how long users spend on a site’s resources. This includes the time elapsed from when a user clicks on a search result to when they navigate back to the search results page, indicating engagement with the content.
- Types of User Interactions: The patent considers different types of user interactions, such as clicks on search results, which can initiate a visit to a resource. The duration of these visits, as measured by various means, contributes to the site quality score.
- Data from Various Sources: The scoring system may utilize data obtained from user devices (like web browsers or browser toolbars), network monitoring systems (such as routers or firewalls), and servers hosting the resources. This comprehensive approach ensures a robust dataset for analysis.
- Adjustments Based on Resource Type: The system can adjust measurements based on the type of resource (e.g., video, image, text) to account for the inherent differences in how users engage with different content types. For example, a longer visit duration might be expected for video content compared to an image.
- Thresholds and Caps: The method includes discarding measurements below a certain threshold or adjusting measurements that exceed a predetermined maximum value. This helps in filtering out outliers and ensuring the data accurately reflects genuine user engagement.
- Suspicious Activity Filtering: Measurements classified as suspicious, possibly indicating non-genuine interactions (like automated bots or spam), are discarded to maintain the integrity of the site quality score.
Additionally, the claim covers various embodiments and enhancements to this basic method, including:
- Adjusting measurements based on factors like the type of resource (e.g., video, text) and user behavior patterns to ensure the score accurately reflects genuine user engagement.
- Discarding measurements that are deemed suspicious or not representative of normal user behavior.
- Using the site quality score in various search engine operations, such as ranking search results, making decisions about which sites to crawl or index, and determining the frequency of site data refreshes in the search index.
Implications for SEO
- User Engagement is Crucial: The emphasis on measuring durations of user visits highlights the importance of creating engaging, high-quality content that keeps users on the site longer. Websites should focus on improving the user experience through relevant, informative, and interesting content that meets the users’ informational needs.
- Diverse Content Types: Given the adjustments based on resource types, diversifying the types of content offered (e.g., incorporating videos, images, and in-depth articles) can cater to different user preferences and engagement patterns, potentially improving the site’s overall quality score.
- Monitoring User Behavior: SEO strategies should include analyzing user behavior metrics, such as bounce rate, average session duration, and pages per session, to understand how users interact with the site. Insights from these analyses can guide content and design improvements.
- Avoiding Manipulative Tactics: The patent’s focus on filtering out suspicious activities underscores the importance of adhering to ethical SEO practices. Attempts to artificially inflate engagement metrics are likely to be identified and disregarded, potentially harming the site’s standing in search results.
- Content Strategy: The scoring system’s ability to adjust based on the proportion of resources of a particular type within a site suggests that having a balanced and strategic approach to content creation can influence the site’s quality score. Content strategies should consider the mix of resource types and their potential impact on user engagement.
- Long-Term SEO: Improving a site’s quality score is a long-term strategy that involves consistently delivering value to users. Quick fixes or short-term tactics are less likely to have a lasting positive impact on search rankings.
Classifying sites as low quality sites
- Patent ID: US9002832B1
- Countries Published For: United States
- Last Publishing Date: April 7, 2015
- Expiration Date: December 1, 2032
- Inventors: Rajan Patel, Zhihuan Qiu, Chung Tin Kwok
This patent describes methods, systems, and computer programs for enhancing search results by classifying sites as low quality based on the quality of links pointing to them. It involves receiving a resource quality score for each resource linking to a site, grouping these resources based on their quality scores, and then using the distribution of these scores across groups to determine a site’s link quality score. If this score is below a certain threshold, the site is classified as low quality.

Claims
The patent claim focuses on a method for classifying websites as low quality based on the evaluation of links pointing to them. This method involves several key steps:
- Receiving a Resource Quality Score: For each resource (such as web pages, documents, etc.) linking to a site, a quality score is received. This score assesses the value or reliability of the linking resource.
- Assigning Resources to Quality Groups: Each linking resource is assigned to a specific group based on its quality score. These groups are predefined ranges of quality, helping to categorize the links from highest to lowest quality.
- Counting Resources in Each Group: The method involves counting how many resources fall into each quality group. This step is crucial for understanding the distribution of link quality pointing to the site.
- Determining a Link Quality Score for the Site: Using the distribution of resources across the quality groups, a link quality score is calculated for the site. This score reflects the overall quality of links pointing to the site.
- Classifying the Site Based on Link Quality Score: If the site’s link quality score falls below a certain threshold, it is classified as a low-quality site. This classification can affect how the site is presented in search results, potentially lowering its visibility or ranking.
From the context of the patent and general practices in SEO and link analysis, we can infer the types of metrics or signals that might be used to create these scores:
- Relevance of Linking Resource: The relevance of the content on the linking page to the content on the target site could be a factor. More relevant links are generally considered higher quality.
- Authority of Linking Resource: The authority or trustworthiness of the website providing the link, often inferred from its own link profile, could influence the quality score. Sites with high authority passing links are likely to contribute positively to the link quality score.
- Link Context: The context within which the link appears on the page, including the surrounding content and its relevance to the linked site, could impact the score. Links embedded within relevant, high-quality content are typically valued more.
- Diversity of Link Sources: The diversity of the linking domains and their relevance to the site’s subject matter might be considered. A broader range of high-quality, relevant sources can enhance the link quality score.
- User Engagement Metrics: Indirectly, user engagement metrics such as click-through rates (CTR) from the linking resource to the site, bounce rates, or other engagement signals might influence the perceived quality of a link.
- Spam Signals: The presence of spammy characteristics or behaviors associated with the linking resource, such as keyword stuffing, hidden links, or participation in link schemes, could negatively affect the resource quality score.
- Link Position on the Page: Links placed in prominent positions on a page, such as within the main content body as opposed to the footer or sidebar, might be assigned higher quality scores.
- Historical Performance: The historical performance of a linking domain in terms of providing quality traffic or being associated with reputable sites might also play a role.

The patent describes a system that likely uses a combination of these and possibly other signals to evaluate the quality of each link and to assign a resource quality score. These scores are then used to group links and ultimately determine the overall link quality score for a site, which can influence its classification as low quality if the score falls below a certain threshold.
Implications for SEO
Quality Over Quantity of Links
The patent underscores the importance of the quality of inbound links rather than just their quantity. SEO strategies should prioritize obtaining links from high-quality, reputable sources that are relevant to the site’s content. This approach is more beneficial than accumulating a large number of low-quality links.
Relevance of Linking Content
Links from resources that are closely related to the content of the target site are likely to be more valuable. SEO efforts should focus on building relationships within the same industry or niche to encourage relevant backlinks, which can positively impact the site’s link quality score.
Avoidance of Link Schemes
The methodology described in the patent makes it clear that manipulative link practices (such as buying links, excessive link exchanges, or using automated programs to create links) can lead to a site being classified as low quality. SEO strategies should avoid such schemes and focus on earning links through high-quality content and genuine community engagement.
Diversification of Link Profile
A diverse link profile, including links from a variety of sources, domains, and contexts, can contribute to a higher link quality score. SEO efforts should aim for a natural-looking link profile with a mix of link types, from different domains, and across various relevant topics.
Monitoring and Disavowing Bad Links
Regular monitoring of a site’s backlink profile is crucial. Identifying and disavowing toxic or low-quality links can help maintain or improve the site’s link quality score. SEO tools that analyze backlink health can be instrumental in this process.
Determining a quality measure for a resource
Patent ID: US9558233B1
Countries Published For: United States
Last Publishing Date: January 31, 2017
Expiration Date: August 16, 2033
Inventors: Hyung-Jin Kim, Paul Haahr, Kien Ng, Chung Tin Kwok, Moustafa A. Hammad, Sushrut Karanjkar
The Google Patent addresses the challenges and methodologies involved in information retrieval on the Internet. Typically, the search results are ordered for viewing based on their rank, which is determined by various factors.
One common approach to ranking resources involves analyzing the number of other resources that include a link to a given resource. Generally, a resource that is linked by a large number of other resources might be ranked higher than one with fewer linking resources. However, this method has its limitations. For instance, some resources may receive a large number of links but do not get corresponding traffic from these links, leading to a disproportionate ranking. This discrepancy highlights the need for more sophisticated methods to accurately measure and rank the quality of resources on the Internet, taking into account not just the quantity of links but also the quality and relevance of these links in relation to actual user engagement and traffic.

Claims
Seed Score Determination: The method involves calculating a seed score for each of a set of seed resources. This score is based on the number of resources linking to the seed resource and the number of times those links are selected. This approach aims to evaluate both the popularity and the engagement with the seed resource.
- Identification of Seed Resources: The process begins with identifying a set of seed resources. These seed resources are selected based on their reliability and the availability of sufficient data regarding links to them and traffic they receive.
- Calculation of Seed Scores: For each seed resource, a seed score is calculated. This score is a reflection of the resource’s popularity and engagement level, derived from two main factors:
- Link Count: The number of other resources that include a link to the seed resource. This count is indicative of the resource’s popularity or recognition on the Internet.
- Selection Count: The number of times the links to the seed resource are actually selected or clicked by users. This count provides insight into the engagement level with the resource, beyond mere recognition.
- Quality of Selections: The determination of a seed score also involves assessing the quality of link selections. This can include analyzing the duration of clicks (short, medium, long clicks), which helps in understanding the depth of user engagement with the seed resource. A longer click duration might indicate more substantial engagement, suggesting higher quality.
- Ratio-Based Scoring: The seed score may be based on a ratio that considers both the number of links to the seed resource and the number of selections of those links. This ratio aims to balance the influence of popularity (as indicated by the number of links) with actual user engagement (as indicated by link selections).
- Selection Quality Score: In some implementations, the process includes determining a selection quality score for each selection of a link to the seed resource. This score is a measure of the quality of the selection, potentially based on factors like click duration. The overall seed score for the resource can then be adjusted based on these selection quality scores, providing a nuanced view of the resource’s value.
- Comprehensive Evaluation: The seed score reflects a comprehensive evaluation of a resource’s quality, factoring in not just how many times it’s linked but also how users interact with those links. This approach aims to identify resources that are not only popular but also genuinely valuable to users.

Source and Resource Scoring: After determining seed scores, the method identifies source resources (resources that link to the seed resources) and calculates a source score for each based on the seed scores of the linked seed resources. Subsequently, source-referenced resources are identified, and a resource score is calculated for each, based on the source scores of the source resources linking to them.
Source Scoring
-
- Identification of Source Resources: After calculating seed scores, the next step involves identifying source resources. These are the resources that include links to the seed resources. Essentially, source resources serve as intermediaries, linking to the high-quality seed resources identified in the first step.
- Calculation of Source Scores: Each source resource is assigned a source score. This score is determined based on the seed scores of the seed resources to which it links. The idea is to assess the quality of source resources by the quality of their outbound links to seed resources. A source resource that links to high-quality seed resources, as evidenced by high seed scores, is likely to be of higher quality itself.
- Quality Propagation: The source score effectively propagates the quality measure from seed resources up to source resources. This step acknowledges that resources contributing to the visibility and traffic of high-quality seed resources are themselves likely to be valuable and trustworthy.
Resource Scoring
-
- Identification of Source-Referenced Resources: For each source resource, the process identifies source-referenced resources. These are the resources that the source resource links to, including both seed resources and additional resources not initially evaluated as seed resources.
- Calculation of Resource Scores: A resource score is then calculated for each source-referenced resource. This score is based on the source scores of the source resources linking to it. The calculation aims to assess the quality of a resource by considering the quality of resources that link to it. If a resource is frequently linked by high-quality source resources, its resource score will be higher, indicating its likely relevance and value.
- Comprehensive Evaluation: This scoring mechanism allows for a comprehensive evaluation of web resources, extending beyond the initial set of seed resources to include a wider array of content. By assessing the interconnectedness and the quality of these connections, the system aims to identify valuable resources across the web.
- Dynamic Scoring: The source and resource scoring process is dynamic, allowing for the continuous reassessment of resource quality as new links are formed and as the quality of linking resources changes over time. This ensures that the search ranking system can adapt to the evolving landscape of the Internet.

Adjustment Based on Scores: The method includes adjusting search result rankings based on the calculated resource scores. This adjustment aims to reflect the quality measure of the resources more accurately in search results.
Adjusting Search Result Rankings
-
- Incorporation of Resource Scores: The core of the adjustment process involves integrating the resource scores into the search ranking algorithm. Resources with higher scores, indicating higher quality and relevance based on the interconnected evaluation of links and user engagement, are given priority in search results. This prioritization reflects a resource’s assessed value to users, aiming to surface the most useful and relevant content.
- Dynamic Ranking Adjustments: The ranking adjustments are dynamic, allowing for real-time changes in search results as the scores of resources update. This flexibility ensures that the search engine can adapt to new information, such as changes in the popularity or relevance of resources, maintaining the relevance and quality of search results over time.
Use of Scores in Ranking Process
-
- Resource Score Influence: The resource score influences the ranking process by serving as a factor in determining the position of a resource in search results. High-scoring resources may be ranked higher than those with lower scores, assuming other factors (such as query relevance) are consistent.
- Adjustment for Specific Queries: The system can also adjust rankings based on the scores for specific types of queries, especially when certain queries are more susceptible to spam or low-quality results. For queries identified as having a higher risk of returning low-quality content, the algorithm may place greater emphasis on resource scores to ensure high-quality results are prioritized.
- Spam Detection and Mitigation: By adjusting rankings based on scores, the system effectively mitigates the impact of spam or manipulative practices intended to artificially inflate the visibility of low-quality content. Resources with inflated link counts but low engagement or quality (as reflected by their scores) can be demoted in search results.
Additional Considerations in Score-Based Adjustments
-
- Thresholds and Categories: The system may use thresholds or categorize resources based on their scores to apply different adjustment strategies. For example, resources that fall below a certain quality threshold might be penalized in rankings, while those exceeding a quality or relevance threshold could receive a boost.
- Contextual Adjustments: Adjustments based on scores can be contextual, taking into account the specific nature of the search query, the user’s search history, and other factors that might influence the relevance and usefulness of search results.
- Feedback Loops: The adjustment process can incorporate feedback mechanisms, where user interactions with search results (such as click-through rates and engagement metrics) further refine and validate the scoring and ranking adjustments. This feedback helps in continuously improving the accuracy and relevance of search results.
Classification and Discounting: Source resources are classified based on their source scores, and the influence of links from certain categories of source resources on the ranking process can be discounted. This step helps in refining the ranking process by considering the quality of the source resources.
Classification of Source Resources
-
- Source Score Threshold: Source resources are classified based on their source scores, which reflect their quality and reliability. A threshold is established to differentiate between high-quality (qualified) and lower-quality (unqualified) sources. This threshold can be dynamically adjusted based on various factors, including the overall quality distribution of source resources.
- Qualified vs. Unqualified Sources: Source resources with scores above the threshold are classified as qualified sources, indicating they are considered reliable and their links are likely to be of high quality. Conversely, sources with scores below the threshold are classified as unqualified, suggesting their links may not be as trustworthy or relevant.
Discounting Process
-
- Discounting Links from Unqualified Sources: The influence of links from unqualified sources on the ranking process is discounted. This means that while these links are still considered, they carry less weight in determining the resource scores and, consequently, the search result rankings. This discounting helps mitigate the impact of spammy or manipulative linking practices.
- Adjusting Resource Scores: For resources that are linked by unqualified sources, their resource scores are adjusted to reflect the discounted value of those links. This adjustment ensures that the ranking of these resources is more accurately aligned with their true value and relevance, free from artificial inflation by low-quality links.
- Dynamic Adjustment Based on Source Classification: The classification of sources and the subsequent discounting of links are dynamic processes. As source scores change over time, sources may be reclassified, and the impact of their links on resource scores and rankings will be adjusted accordingly. This dynamic approach allows the search engine to adapt to changes in the web’s ecosystem and maintain the quality of search results.
Use of Anchor Text and N-Grams: The method extends to analyzing anchor text for links in source resources, identifying n-grams (sequences of text) within the anchor text, and assigning scores to these n-grams based on the source scores. This detailed analysis contributes to a more nuanced understanding of the relevance and quality of links.
Analyzing Anchor Text
-
- Anchor Text Identification: The process begins with identifying the anchor text for each link present in a source resource. Anchor text provides contextual clues about the content of the linked resource and is a critical factor in understanding the relevance and quality of the link.
- Contextual Relevance: By analyzing the anchor text, the system can assess the contextual relevance of a link to both the source and target resources. This relevance is crucial for determining the quality of the link and its contribution to the target resource’s value.
N-Gram Extraction and Scoring
-
- Extraction of N-Grams: From the identified anchor text, the system extracts n-grams. This involves breaking down the anchor text into sequences of words or characters (for example, bi-grams for sequences of two, tri-grams for sequences of three, etc.). This breakdown allows for a granular analysis of the text.
- N-Gram Scoring: Each n-gram is then assigned a score based on the source scores of the source resources that include the n-gram in their anchor text. This scoring reflects the collective quality measure of the contexts in which the n-gram appears, providing insights into the relevance and trustworthiness of the n-gram with respect to the linked content.
Application in Search Ranking
-
- Enhancing Resource Scores: The n-gram scores can be used to adjust the resource scores of the linked resources. If a resource is frequently linked with high-scoring n-grams, it may indicate that the resource is of high quality and relevance, warranting a higher resource score.
- Query Relevance: The analysis of n-grams also plays a crucial role in understanding the relevance of resources to specific search queries. By matching the n-grams in anchor texts to the terms in search queries, the system can better assess which resources are most relevant to the user’s intent.
- Adjusting Search Results: The relevance and quality scores derived from anchor text and n-gram analysis can be used to adjust the ranking of search results. Resources linked with high-quality, relevant anchor texts (as indicated by high n-gram scores) may be ranked higher, as they are deemed more valuable to users.
Query and Search Result Adjustment: The method also includes adjusting the ranking of search results for specific queries based on the scores of n-grams found in the query, allowing for dynamic adjustments of search results based on the query’s content and the quality measures of linked resources.

Adjusting Search Results Based on Query Analysis
-
- Query Scoring: The system begins by analyzing the search query itself, breaking it down into components such as n-grams (sequences of words or characters) and assessing these components for relevance and quality. Each component of the query is scored, potentially based on the n-gram scores derived from anchor text analysis, indicating the quality and relevance of resources associated with these n-grams.
- Query-Specific Adjustments: Based on the scores associated with the query components, the search engine adjusts the ranking of search results. This adjustment is designed to prioritize resources that are not only relevant to the query terms but also of high quality, as indicated by their resource scores and the relevance of the n-grams within them.
Dynamic Ranking Adjustments
-
- Incorporation of Resource and N-Gram Scores: The adjustment process takes into account the scores of resources linked to the query terms, as well as the n-gram scores from anchor text analysis. This comprehensive approach ensures that the search results reflect both the relevance of resources to the query and the overall quality of these resources.
- Relevance and Quality Balance: The system balances relevance (how closely resources match the query terms) with quality (the assessed value of these resources based on link analysis and user engagement). This balance is crucial for delivering search results that not only meet the user’s immediate informational needs but also represent trustworthy and valuable content.
Spam Detection and Mitigation
-
- Spam-Related Adjustments: For queries that are particularly susceptible to returning spammy or low-quality results, the system may apply more stringent adjustments based on the quality scores. This approach helps to mitigate the impact of spam and ensure that users are presented with high-quality, relevant information.
- Adjustment Based on Propensity for Spam: The system can adjust the weighting of certain factors, such as the influence of link counts versus user engagement metrics, based on the propensity of a query to surface spam-related search results. This dynamic adjustment helps to counteract attempts to manipulate search rankings through spammy practices.
Implications for SEO
Quality and Relevance Over Quantity
- Link Quality: The emphasis on evaluating the quality of links to and from a resource suggests that SEO strategies should prioritize obtaining high-quality backlinks from reputable sources over merely increasing the number of links.
- Content Relevance: The analysis of anchor text and n-grams highlights the importance of contextually relevant links. SEO efforts should ensure that anchor texts are descriptive and relevant to the linked content.
User Engagement Metrics Matter
- Engagement Over Clicks: The patent outlines the use of engagement metrics, such as the duration of clicks, to assess the quality of interactions with a resource. SEO strategies should focus on creating content that not only attracts clicks but also engages users, encouraging them to spend more time on the page.
Mitigation Against Spam and Manipulation
- Avoidance of Spammy Practices: The patent’s focus on detecting and mitigating spam-related content and links underscores the importance of adhering to ethical SEO practices. Attempts to manipulate rankings through spammy links or practices are likely to be penalized.
Importance of Comprehensive SEO Strategies
- Holistic Approach: Successful SEO strategies must take a comprehensive approach, considering not just keywords and links but also the quality of content, user engagement, and the overall user experience. This holistic approach aligns with search engines’ goal of providing users with the most relevant and high-quality results.
Site quality score
- Patent ID: US9760641B1
- Countries Published: United States
- Last Publishing Date: September 12, 2017
- Expiration Date: September 8, 2032
- Inventors: April R. Lehman, Navneet Panda
The patent relates to the field of ranking search results from internet search queries. Internet search engines aim to identify and present resources (such as web pages, images, text documents, and multimedia content) that are relevant to a user’s information needs. The patent addresses the challenge of determining the quality of websites (or other collections of data resources) as seen by a search engine, which is crucial for effectively ranking these resources in search results to meet user expectations. The background sets the stage for introducing the patent’s solution to computing a site quality score based on user interactions, which can then be used to rank resources or search results associated with those sites.
Claims
Determining Unique Queries: The process involves calculating a first count of unique queries that refer to a particular site and a second count of unique queries associated with the site. A query is considered to refer to a site if it includes a reference to that site, such as a site label or a term identified as referring to the site. A query is associated with the site if it leads to a user selection of a search result identifying a resource on that site.
Determining Counts of Unique Queries
The process begins by determining two distinct counts of unique queries related to a particular site:
-
- First Count: This involves counting unique queries that include a reference to the particular site. A query is considered to include a reference to the site if it explicitly mentions the site through a site label or if it includes terms that have been identified as referring to the site. This count reflects direct user interest in the site.
- Second Count: This count involves queries that are associated with the site, where association is determined by user actions following the query. Specifically, a query is associated with the site if it leads to a user selecting a search result that identifies a resource on the site. This count reflects user interest in the content or resources provided by the site.
Computing the Site Quality Score: The site quality score is determined based on the first and second counts of unique queries. This involves computing a ratio where the numerator represents user interest in the site as indicated by queries directed to the site, and the denominator represents user interest in the resources found on the site as responses to all types of queries.
Computing the Ratio
The site quality score is computed by forming a ratio of the first count to the second count. This ratio aims to quantify the site’s quality by comparing direct interest in the site (as indicated by queries referring to the site) against the broader interest in the content or resources of the site (as indicated by queries leading to selections of site content). The computation involves several steps:
-
- Numerator: The first count, possibly adjusted by a threshold value, represents the numerator. This adjustment can account for a baseline level of interest or to normalize the data.
- Denominator: The second count forms the denominator, which may also be adjusted. The adjustment could involve raising the count to a power that is greater than zero but less than one, or adding a base value before applying the power. These adjustments can help to moderate the impact of very high or very low counts, ensuring that the score remains meaningful across sites with varying levels of user interaction.
Optional Adjustments
The patent details optional features for refining the computation of the site quality score:
-
- Threshold Adjustments: The first count can be reduced by a threshold value to ensure that only significant interest is considered. Similarly, the second count can be adjusted to reflect the depth of user engagement with the site’s resources.
- Lower-Bound Values: The numerator can be set to a maximum of a lower-bound value and the adjusted first count, ensuring that the score does not fall below a certain level due to lack of direct queries.
- Power Adjustments: The denominator’s adjustment by raising the second count to a power less than one allows for a nonlinear scaling, which can help in differentiating between sites with marginally different levels of user engagement.
Use of Site Quality Score: The calculated site quality score can be used as a signal to rank resources or search results that identify resources found on one site relative to those found on another site. This allows for the adjustment of search result rankings based on the perceived quality of the sites.
Ranking Search Results
The primary application of the site quality score is in the ranking of search results. Search engines aim to provide users with the most relevant and high-quality results for their queries. By incorporating the site quality score as a signal in their ranking algorithms, search engines can adjust the visibility of resources or web pages based on the perceived quality of their host sites. This means that if a site has a high quality score, indicating strong user interest and engagement, its content may be ranked higher in search results compared to similar content from sites with lower quality scores.
Enhancing Search Algorithms
The site quality score can be used to refine various components of search algorithms beyond just ranking:
-
- Relevance Matching: It can help in better aligning search results with user expectations by prioritizing sites that users have demonstrated a preference for through their search behaviors.
- Personalization: For users who are logged in or have a history with the search engine, the site quality score can be used to personalize search results further, emphasizing sites and resources that align with their demonstrated interests.
Quality Filtering
In addition to influencing rankings, the site quality score can serve as a filter to improve the quality of search results. Sites with consistently low quality scores, which may indicate low relevance or poor user experience, could be demoted or filtered out from top search results. This helps maintain a high standard of quality in the search results presented to users.
Feedback Loop for Webmasters
Although not explicitly mentioned in the patent, the concept of a site quality score could also provide valuable feedback to webmasters and SEO professionals. Understanding that search engines consider user engagement and interest in site quality assessments could encourage the development of more user-centric content and site improvements aimed at increasing user satisfaction and engagement.
Dynamic Adjustment
The site quality score is not static; it can change based on ongoing user interactions and behaviors. This dynamic nature allows search engines to adapt to changes in user preferences and the evolving web landscape. Sites that improve their content and user experience can see improvements in their quality scores over time, potentially leading to better search rankings.
Implementation Details: The claims also detail how a query is determined to include a reference to a particular site, including the use of site labels or terms that have been determined to refer to the site. Additionally, the claims cover the technical aspects of implementing the methods, including the use of computer systems, apparatus, and computer programs recorded on one or more computer storage devices configured to perform these operations.
Optional Features: Some claims include optional features such as adjusting the counts by a threshold value, computing the ratio using modified counts, and considering user selections of search results as part of the association with a particular site.
Implications for SEO
1. User Engagement as a Ranking Factor:
The patent underscores the importance of user engagement and interaction as factors in determining the quality of a site. SEO strategies must therefore evolve to prioritize not just content and keyword optimization but also user experience (UX) design, site usability, and engagement metrics such as click-through rates (CTR), time on site, and bounce rates.
2. Content Quality and Relevance:
To improve a site’s quality score, content must be highly relevant to user queries. This means creating content that directly addresses the needs and questions of the target audience, rather than focusing solely on keyword density or traditional on-page SEO factors. High-quality, engaging content is more likely to attract queries specifically targeting the site, as well as user interactions that signal relevance and value to search engines.
3. Site Structure and Navigation:
A well-organized site structure and intuitive navigation can enhance user engagement by making it easier for visitors to find the information they need. This can lead to increased user satisfaction, longer visit durations, and more interactions with the site—all of which can positively impact the site quality score.
4. Brand Recognition and Search Behavior:
The patent highlights the role of brand recognition in search behavior, as queries may include references to specific sites or brands. SEO strategies should therefore also focus on building brand awareness and loyalty, encouraging users to include brand names in their search queries or directly navigate to the site through search engines.
5. Personalization and User Intent:
With the site quality score taking into account user interactions that reflect interest in specific sites, SEO strategies must also consider user intent and personalized search experiences. Tailoring content to meet the varied intents behind search queries—informational, navigational, transactional—can improve user engagement and contribute to a higher site quality score.
7. Feedback and Continuous Improvement:
The dynamic nature of the site quality score means that SEO is an ongoing process of monitoring, analysis, and adjustment. Websites must continuously seek feedback through analytics, user surveys, and performance metrics to identify areas for improvement and adapt their SEO strategies accordingly.
Patent ID: US9244972B1
Countries Published For: United States
Last Publishing Date: January 26, 2016
Expiration Date: November 30, 2033
Inventors: Lakshmi N. Chakrapani, April R. Lehman, Neil C. Fernandes
The patent identifies a specific type of query, termed “hybrid queries,” which blend characteristics of both informational and navigational queries. Informational queries are those where the user is seeking information on a topic, while navigational queries are aimed at finding a specific website or page. A significant focus is on identifying navigational resources for specific topics based on past user queries. This involves analyzing recorded queries to determine which resources users navigate to when searching for information on particular topics.

Claims
Hybrid Query Processing
- The patent claims a method for processing search queries by identifying hybrid queries. These are queries that include both a topic keyword (indicating the subject of interest) and a navigation keyword (pointing to a specific navigational resource).
- It involves creating a mapping between topics and navigational resources based on these hybrid queries.

Mapping Creation and Utilization
- A first mapping is created by associating navigational resources with groups of topics identified in hybrid queries. This mapping is then used to generalize topics and augment associations, effectively broadening the scope of topics linked to specific navigational resources.
- A second mapping is generated by inverting the first, associating topics with groups of navigational resources. This second mapping is used to score and rank search results, potentially improving the relevance of search outcomes for users.
Mapping Creation
The process begins with the analysis of query logs to identify hybrid queries. These queries contain both a topic keyword (which identifies a specific topic of interest to the user) and a navigation keyword (which points to a specific navigational resource, such as a website or webpage).
A first mapping is created by associating unique navigational resources identified in the hybrid queries with groups of topics. Each association in this mapping links a navigational resource to one or more topics identified in the hybrid queries that also mention that resource. This step essentially maps out which resources are relevant to which topics based on user behavior.
The process then involves generalizing the topics associated with each navigational resource to include additional topics not originally present in the group. This means expanding the scope of topics that a particular navigational resource is associated with, based on similarities or relatedness to the topics already identified. The associations are augmented to include these additional topics, thereby broadening the relevance of each navigational resource.
The first mapping is then inverted to create a second mapping. This second mapping associates topics with groups of navigational resources, essentially flipping the perspective of the first mapping. Now, for each topic, there is a list of navigational resources that are relevant to that topic.
Mapping Utilization
The second mapping is used to score candidate search results for new search queries. This involves evaluating the relevance of navigational resources to the topic of the query and using the associations and their scores to rank the search results. The goal is to prioritize navigational resources that are most relevant and useful to the user’s query.
The mappings allow the search engine to adjust the ranking of search results based on the established associations between topics and navigational resources. Resources with a higher relevance to the queried topic, as determined by the mappings, may be ranked higher in the search results, making them more visible to the user.
By leveraging these mappings, the search engine can more accurately match user queries with the most relevant navigational resources. This not only improves the user experience by reducing the need for multiple search attempts to find the desired information but also helps in directing traffic to websites that are most relevant to the user’s needs.

Scoring and Ranking Enhancements
- The patent details methods for calculating association scores for navigational resources within the mappings. These scores are based on factors like click counts, query revisions from informational to navigational queries, and the presence of topic keywords in the anchor text of hyperlinks pointing to navigational resources.
- These scores are then used to adjust the ranking of search results, aiming to present users with more relevant navigational options based on their informational queries.
Calculating Association Scores
The process begins with filtering initial associations between topics and navigational resources based on precision criteria. These criteria might include factors like the proportion of clicks a navigational resource receives from hybrid queries related to a specific topic, the number of search sessions showing a transition from an informational query to a navigational query for the resource, and the minimum number of clicks or interactions required for a resource to be considered relevant to a topic.
After filtering, an initial topic-to-resource mapping is created. This mapping includes associations between unique topics and groups of navigational resources, where each resource is linked to a topic based on the filtered associations.
This initial mapping is then inverted to form the basis for scoring, similar to the first mapping process described earlier. This inversion associates topics with navigational resources, setting the stage for calculating association scores.
Using Association Scores in Scoring Search Results
For each navigational resource associated with a topic, the system calculates an association score. This score reflects the resource’s relevance and importance to the topic, based on various factors such as:
- The total number of clicks received from informational queries related to the topic.
- The frequency of search session transitions from informational to navigational queries for the resource.
- The count of unique topics associated with the resource, indicating its broad relevance.
- The presence of the topic keyword in the anchor text of hyperlinks pointing to the resource, suggesting its authority or popularity in relation to the topic.
The calculated association scores are then used to score candidate search results for new queries. This involves adjusting the relevance score of navigational resources based on their association scores, potentially boosting their ranking in search results when they are deemed highly relevant to the queried topic.
The enhanced scoring system allows for a more dynamic and context-sensitive ranking of search results. Navigational resources with high association scores for a queried topic are ranked higher, making them more visible to users. This prioritization is based on the premise that resources frequently associated with a topic through user interactions are likely to be of higher quality or relevance.
Vertical and Author Mappings
- Additional claims include the creation of vertical-to-resource mappings and topic-to-author mappings. These mappings further refine how resources are associated with specific topics or subject areas (verticals) and how authors are linked to topics based on authorship claims on the internet.
- These mappings can be used to score search results for queries falling into specific verticals or related to the works of specific authors, enhancing the personalization and relevance of search results.
 Vertical Mappings
Vertical Mappings
The process involves categorizing each unique topic identified in the topic-to-resource mappings into one or more specific verticals. Verticals are broad categories that represent areas of interest or industries, such as health, finance, technology, etc. This categorization helps in organizing topics and their associated resources into more manageable and relevant groups.
Once topics are categorized into verticals, the patent describes creating vertical-to-resource mappings. These mappings associate each vertical with a group of navigational resources that are relevant to the topics within that vertical. It’s a way of saying, “For the health vertical, these are the key resources that are most relevant based on user queries and interactions.
The vertical-to-resource mappings are then used to score candidate search results for queries that fall into one of the categorized verticals. This means that if a user’s query is identified as belonging to the health vertical, the search engine can prioritize resources that are mapped to the health vertical, potentially improving the relevance of the search results.
Author Mappings
Beyond categorizing topics into verticals, the patent also explores the idea of linking topics to authors. This involves processing query logs to identify queries that include terms related to specific topics and authors. For each author, the system identifies resources on the internet for which the author has claimed authorship.
If a significant amount of clicks are received by search results pointing to resources authored by a specific person, a topic-to-author association is created. This links the topic directly to the author, suggesting that the author is a relevant and authoritative source for information on that topic.
The topic-to-author mapping is then used to score search results for queries related to the topics. Resources authored by the associated authors may receive a higher relevance score, reflecting their authority and expertise on the topic. This can lead to higher visibility in search results for queries related to the author’s area of expertise.
User Interface Elements
- The patent also claims methods for providing user interface elements on search result pages that identify navigational resources associated with topics of user-submitted queries. This includes enhancements to search input interfaces, like scoring candidate auto-completions for partially completed queries based on the mappings.
Implications for SEO
1. Emphasis on Topic Authority and Relevance:
- SEO strategies will need to focus more on establishing topic authority and relevance. This means creating content that not only covers a topic comprehensively but also aligns closely with user intent and query patterns. Websites should aim to become recognized navigational resources for specific topics within their industry or niche.
2. Importance of User Behavior Analysis:
- Understanding user behavior, such as how users transition from informational to navigational queries, becomes crucial. SEO professionals should analyze search query logs (where accessible) and use tools that simulate this analysis to optimize content in a way that meets user needs and matches their search behaviors.
3. Vertical-Specific SEO:
- The concept of vertical mappings underscores the importance of vertical-specific SEO strategies. Websites should tailor their content and SEO efforts to align with the specific verticals they belong to, optimizing for the unique characteristics, keywords, and user expectations of those verticals.
4. Authorship as a Ranking Factor:
- The idea of author mappings highlights the potential importance of authorship as a ranking factor. Content creators and websites should clearly attribute content to authors with recognized expertise and authority in the topic area. Building a strong personal brand for authors could directly benefit the SEO performance of the content they produce.
5. Content and Link Quality:
- The enhanced scoring and ranking mechanisms suggest that the quality of content and the context of inbound links (including anchor text relevance) will continue to be critical. SEO efforts should focus on generating high-quality, informative content that attracts clicks and engagement, as well as earning links from reputable sources within the same topic area or vertical.
Ranking Search Results Based on Entity Metrics
The patent ID is US10235423B2. The patent was officially issued on March 19, 2019. The inventors listed are Hongda Shen, David Francois Huynh, Grace Chung, Chen Zhou, Yanlai Huang, and Guanghua Li, all associated with Google LLC, Mountain View, CA, USA. It is published for US and WIPO. This means that it is more likely to be used in practice.
For me this is the basic patent for the algorithmic implementation for E-E-A-T ratings.
Background:
The patent addresses the challenge of effectively ranking search results in a way that is both relevant and valuable to the user. It recognizes the limitations of existing methods in adequately distinguishing between the nuances of different types of entities and their corresponding metrics in search results.

Core Insights:
- Purpose: The patent outlines methods, systems, and computer-readable media for ranking search results through determining various metrics based on the search results. It particularly emphasizes the weighting of these metrics based on the type of entity included in the search, suggesting a nuanced approach to search result ranking.
- Process: A score is determined by combining metrics and weights, where weights are partly based on the entity type in the search query. This score is then used to rank the search results, indicating a dynamic and adaptable ranking mechanism that takes into account both quantitative metrics and qualitative assessments of entity types.
- Factors: The patent details several key metrics such as related entity metric, notable type metric, contribution metric, prize metric, and domain-specific weights. These metrics collectively contribute to the final scoring and ranking of search results.

Summary:
The document elaborates on a sophisticated method for ranking search results by:
- Determining several metrics based on the search results.
- Assigning weights to these metrics, where the weights are influenced by the type of entity featured in the search.
- Combining these metrics and weights to derive a score.
- Ranking the search results based on this score.
Claims:
The claims of the patent are focused on the specific processes for determining the various metrics (related entity metric, notable type metric, contribution metric, prize metric), the method of calculating domain-specific weights, and the overall scoring mechanism that underpins the ranking of search results.
The entity metrics
The claims of the patent are focused on the specific processes for determining the various metrics (related entity metric, notable type metric, contribution metric, prize metric), the method of calculating domain-specific weights, and the overall scoring mechanism that underpins the ranking of search results.
- Related Entity Metric: This metric is determined based on the co-occurrence of an entity reference contained in a search query with the entity type of the entity reference on web pages. For example, if the search query contains the entity reference “Empire State Building,” which is determined to be of the entity type “Skyscraper,” the co-occurrence of the text “Empire State Building” and “Skyscraper” in webpages may determine the relatedness metric.
- Notable Type Metric: This metric is a global popularity metric divided by a notable entity type rank. The notable entity type rank indicates the position of an entity type in a notable entity type list, showing the importance or prominence of the entity type in a given context.
- Contribution Metric: Based on critical reviews, fame rankings, and other information, the contribution metric is weighted such that the highest values contribute most heavily to the metric. This metric assesses the contribution or significance of the entity or content in its respective domain.
- Prize Metric: Reflects recognition or awards associated with the entity, where specific domains like movies may include metrics associated with particular movie awards. The metric values could be determined based on system settings, aggregated user selections of entity references, and data associated with entity references.
These metrics are combined with domain-specific weights to determine a comprehensive score, which is then used to rank the search results. The system’s approach to defining and applying these metrics emphasizes the importance of both quantitative and qualitative analysis of entities and their relationships within the search context.
Implications for SEO
In conclusion, the detailed entity metrics and their application in ranking search results call for a holistic and nuanced approach to SEO. This approach should prioritize entity recognition, content quality and relevance, structured data, and external validations, all tailored to the specific demands of the domain in question.
- Entity-Based Search Optimization: SEO strategies must evolve to focus more on entity-based content optimization. This means understanding how search engines recognize and categorize entities within content and optimizing for these entities in addition to traditional keywords.
- Content Relevance and Quality: The use of metrics like the related entity metric and notable type metric indicates that search engines are looking at the relevance and authority of content in a much more granular way. For SEO, this means prioritizing high-quality, authoritative content that accurately reflects the entities discussed.
- Structured Data and Schema Markup: Implementing structured data and schema markup becomes even more crucial as these tools help search engines understand the entities within a page and how they relate to each other. This can enhance content’s visibility in search results that are increasingly entity-focused.
- Diverse and Comprehensive Content: With metrics assessing contributions and prizes (or recognitions), content that covers a wide range of related topics and includes comprehensive discussions of entities (including their achievements and recognitions) may rank higher. This implies that SEO strategies should include creating in-depth content that covers entities from multiple angles.
- Social Signals and External Validation: The inclusion of metrics related to prizes and contributions suggests that external validation (such as awards, mentions, reviews, and social media signals) plays a role in content ranking. SEO efforts should thus consider how to garner positive external recognition and citations from reputable sources.
- Domain-Specific Optimization: The patent hints at domain-specific weights for metrics, suggesting that what’s important for ranking can vary significantly across different content types or industries. SEO professionals need to understand the specific ranking factors that matter most in their domain and optimize accordingly.
- Adapting to Search Engine Evolution: The patent reflects the ongoing evolution of search engines towards understanding and serving user intent through a deeper understanding of content and context. SEO strategies must be flexible and adaptable, focusing on future-proofing content by making it as relevant, authoritative, and user-focused as possible.
This Google patent first published in May 2017. The patent focuses on improving search engine results by incorporating authoritative search results. This is achieved by identifying resources on authoritative sites relevant to a user’s query and integrating these into the search results.
- Search Query Processing: The system receives a search query and generates initial search results.
- Identification of Authoritative Results: It identifies authoritative search results, which are resources from sites considered authoritative for the specific query.
- Ranking and Integration: These authoritative results are then ranked alongside the initial search results and presented to the user.

Scoring Process and Factors
- Initial Search Results Scoring:
- The system first generates a set of initial search results in response to a user’s query.
- Each of these results is scored based on relevance, which could include factors like keyword matching, content quality, user engagement metrics, and other SEO factors.
- Identification of Low Scores:
- The system evaluates the scores of these initial search results.
- If the scores are generally low or do not meet a certain threshold, it triggers the need for authoritative search results.
- Authoritative Search Results:
- The system then looks for authoritative search results, which are resources from sites considered authoritative for the specific query.
- This involves a mapping between keywords and authoritative sites. When a term from the query matches a keyword in this mapping, the corresponding authoritative site is identified.
- Confidence Scores for Authoritative Sites:
- Each authoritative site associated with a keyword is assigned a confidence score.
- This score represents the likelihood that the keyword, if received in a query, refers to that authoritative site.
- Query Refinement Analysis:
- The system also analyzes how users refine their queries.
- If users frequently refine a query to include a specific keyword and then navigate to a particular site, this site might be added to the mapping for that keyword.
- Ranking of Authoritative Results:
- Once authoritative results are identified, they are ranked. This ranking can be influenced by various factors:
- Modified IR Scores: If the initial Information Retrieval (IR) score for an authoritative result is low, it might be modified to better reflect its relevance to the query.
- Demotion Factors: These are applied based on the similarity between the original and revised queries. A lower similarity score might result in a higher demotion factor, affecting the ranking of the authoritative result.
- Confidence Scores: The confidence score of the authoritative site also plays a role in ranking.
- Once authoritative results are identified, they are ranked. This ranking can be influenced by various factors:
- Integration with Initial Results:
- Finally, the authoritative search results are integrated with the initial search results.
- The combined set of results is then presented to the user, with the ranking reflecting both relevance and authority.

Implications for SEO
It emphasizes the importance of not only optimizing for keywords and content relevance but also establishing authority in specific niches. Sites that are recognized as authoritative for certain keywords or topics are more likely to be surfaced in search results, especially when standard results do not meet quality thresholds. This underscores the need for high-quality, trustworthy content and the strategic use of keywords that align with the site’s expertise and authority.
- Focus on Authority: Websites should aim to become authoritative in their niche, as search engines might prioritize their content for relevant queries.
- Keyword Relevance: Aligning content with keywords that are mapped to authoritative sites can increase visibility.
- Quality over Quantity: High-quality, reliable content is more likely to be recognized as authoritative.
- Adaptability: SEO strategies should consider how search engines might interpret the authority of content based on query context.
This patent seems to me the foundation for the E-E-A-T concept.
Producing a ranking for pages using distances in a web-link graph
This Google patent was resigned by Google in 2017 in the latest version and the status is active. The patent describes how a ranking score for linked documents can be produced based on the proximity to manually selected seed sites. In the process, the seed sites themselves are individually weighted.
In a variation on this embodiment, a seed page si in the set of seed pages is associated with a predetermined weight wherein 0<wi≦1. Furthermore, the seed page si is associated with an initial distance di wherein di=−log(wi).
The seed pages themselves are of high quality or the sources have a high credibility. You can read the following about these pages in the patent:
In one embodiment of the present invention, seeds 102 are specially selected high-quality pages which provide good web connectivity to other non-seed pages. More specifically, to ensure that other high-quality pages are easily reachable from seeds 102, seeds in seeds 102 need to be reliable, diverse to cover a wide range of fields of public interests, as well as well-connected with other pages (i.e., having a large number of outgoing links). For example, Google Directory and The New York Times are both good seeds which possess such properties. It is typically assumed that these seeds are also “closer” to other high-quality pages on the web. In addition, seeds with large number of useful outgoing links facilitate identifying other useful and high-quality pages, thereby acting as “hubs” on the web.
According to the patent, these seed pages must be selected manually and the number should be limited to prevent manipulation. The length of a link between a seed page and the document to be ranked can be determined e.g. by the following criteria:
- the position of the link
- the font of the link
- degree of thematic deviation of the source page
- number of outgoing links of the source page
It is interesting to note that pages that do not have a direct or indirect link to at least one seed page are not even included in the scoring.
This also allows conclusions to be drawn as to why some links are included by Google for ranking and some are not.
Note that however, not all the pages in the set of pages receive ranking scores through this process. For example, a page that cannot be reached by any of the seed pages will not be ranked.

This concept can be applied to the document itself, but also to the publisher, domain or author in general. A publisher or author that is often directly referenced by seed sites gets a higher authority for the topic and semantically related keywords from which it is linked. These seed sites can be a set of sites per topic that are either manually determined or reach a threshold of authority and trust signals.
Combating Web Spam with Trust Rank
 The scientific paper “Combating Web Spam with Trust Rank” describes how further trustworthy seed sites can be identified automatically on the basis of a manual selection of a set of a maximum of 200 seed sites.
The scientific paper “Combating Web Spam with Trust Rank” describes how further trustworthy seed sites can be identified automatically on the basis of a manual selection of a set of a maximum of 200 seed sites.
Our results show that we can effectively filter out spam from a significant fraction of the web, based on a good seed set of less than 200 sites.
A human expert then examines the seed pages, and tells the algorithm if they are spam (bad pages) or not (good pages). Finally, the algorithm identifies other
pages that are likely to be good based on their connectivity with the good seed pages.
The algorithmic determination of further trusted sites follows the assumption that trusted sites do not link to spam sites on their own, but to other trusted sources.
Search result ranking based on trust
The patent US8818995B1 is published in the United States. The last publication date for this patent is August 26, 2014.
The inventors listed for this patent are:
- Andrew W. Hogue
- John D. DeTreville
- Orion Letizi
The patent addresses a fundamental challenge in the design and functionality of search engines: the relevance of search results is highly dependent on the user’s intent and circumstances, which vary significantly among users. Traditional search engines often struggle to accurately infer a user’s intent based solely on the query terms provided. This limitation stems from the fact that intent can be influenced by numerous situational factors that are not readily apparent from the query itself.
Attempts to solve this problem have typically relied on relatively weak indicators of user intent, such as static user preferences or predefined methods of query reformulation. These approaches are based on educated guesses about what the user might be interested in, based on the terms used in the search query. However, they fall short because user intent is highly variable and dependent on factors that cannot be easily extrapolated from the query terms alone.
As a result of these limitations, users often turn to specialized websites, known as vertical knowledge sites, for more tailored and relevant information. These sites, which can range from community forums for shared interests to expert blogs in specific fields, offer additional analysis or understanding of content available on the Internet. They allow users to link to content, provide labels or tags describing the content, and host comments and analysis from experts or knowledgeable individuals. This approach helps users find information that is more closely aligned with their specific needs and interests.
However, the problem persists when users return to general search engines, as these platforms are unable to incorporate the trustworthiness of documents or the credibility of associated commentary and opinions into their search results. This disconnect means that the additional context and reputation-based information available on vertical knowledge sites are not utilized by general search engines to enhance the relevance and reliability of search results for users.
Claims
The claims of patent outline a method and system for enhancing search engine results by incorporating trust relationships and annotations into the ranking process. The key aspects of the claims include:
- Determining Trust Relationships: The method involves determining trust relationships based on a user’s web visitation patterns. These trust relationships indicate that the user trusts certain entities, and the strength of these relationships can increase or decrease over time based on the user’s interactions with web pages associated with these entities.
- Updating Trust Relationships: The system updates the set of trust relationships for a user, where the strength of a trust relationship with an entity can decrease due to the passage of time or remain unchanged based on the user’s continued engagement with web pages associated with a second entity.
- Identifying Resources and Annotation Label Terms: The method includes identifying resources (such as documents or web content) responsive to a search query. Each resource is associated with one or more annotation label terms, which are matched against terms of the search query.
- Determining Trust Ranks: For each annotation label term that matches a term of the search query, a trust rank is identified. This trust rank indicates the strength of the trust relationship between the user and the entity that associated the annotation label term with the resource. The trust ranks are based on the trust relationships determined from the user’s web visitation patterns.
- Ranking Resources Based on Trust Ranks: The resources are ranked based on the trust ranks associated with the annotation label terms. This ranking process takes into account the strength of the trust relationships between the user and the entities that have provided annotations, thereby providing search results that are tailored to the user’s trusted sources.
In the Google patent Search result ranking based on trust there are references to the use of anchor texts as a trust score.
The patent describes how the ranking scoring of documents is supplemented based on a trust label. This information can be from the document itself or from referring third-party documents in the form of link text or other information related to the document or entity. These labels are associated with the URL and recorded in an annotation database.
Google itself has also confirmed that the anchor texts of links not only increase the relevance of the target page itself, but can have a positive effect on the entire domain.

Implications for SEO
- Emphasis on Trustworthiness: SEO strategies would need to prioritize not just the relevance and quality of content but also its perceived trustworthiness. Websites and content creators might need to focus on building trust with their audience through transparent practices, authoritative backlinks, and endorsements from trusted entities.
- Annotations and Labels: The use of annotations or labels by trusted entities to describe web content suggests that metadata and tagging strategies could become more crucial. SEO efforts may need to include optimizing such labels to match the search queries of users who trust those entities, potentially influencing how content is categorized and discovered.
- User Engagement and Interaction Patterns: Since the patent suggests that trust relationships can be determined based on a user’s web visitation patterns, SEO strategies might increasingly focus on user engagement and retention. Encouraging repeat visits and prolonged engagement with content could signal trustworthiness to search engines.
- Reputation Management: The importance of reputation, both online and offline, could have a greater impact on SEO. Managing and improving the reputation among users and trusted entities could directly influence search rankings. This might involve more active engagement with communities, experts, and influencers in relevant fields.
- Collaboration with Trusted Entities: Forming partnerships or collaborations with entities that users trust could become a strategy for improving SEO. Being featured or endorsed by such entities, or having content annotated by them, could boost the trust rank of a website or its content.
- Quality and Depth of Content: To attract annotations and positive engagement from trusted entities and users, the quality and depth of content will remain paramount. High-quality, informative, and authoritative content is more likely to be recognized and labeled by trusted entities, enhancing its visibility in search results.
For me this Google patent is the most interesting one according to E-E-A-T. In Credibility of an author of online content, reference is made to several factors that can be used to algorithmically determine the credibility of an author. This Google patent has the status “Application status is active”.
The internet’s vast and democratic nature allows for a proliferation of content, ranging from high-quality to low-quality information. The patent addresses the challenge of identifying and promoting high-quality content by assessing the credibility of content authors. It notes the difficulty in distinguishing reputable authors from those who may misrepresent their knowledge or identity online.
It describes how a search engine can rank documents under the influence of a credibility factor and reputation score of the author.
- An author can have several reputation scores, depending on how many different topics he publishes content on. That is, an author can have reputation for multiple topics.
- The reputation score of an author is independent of the publisher.
- The reputation score can be downgraded if duplicates of content or excerpts are published multiple times.
In this patent there is again a reference to links as a possible factor for an E-E-A-T rating. So the reputation score of an author can be influenced by the number of links of the published content.
The following possible signals for a reputation score are mentioned:
- How long the author has a proven track record of producing content in a topic area.
- how well known the author is
- Ratings of the published content by users
- If content of the author is published by another publisher with above-average ratings
- The number of content published by the author
- How long it has been since the author’s last publication
- The ratings of previous publications of similar topic by the author
More interesting information about reputation score from the patent:
- An author can have multiple reputation scores depending on how many different topics they publish content on.
- The reputation score of an author is independent of the publisher.
- Reputation score can be downgraded if duplicate content or excerpts are published multiple times.
- The reputation score can be influenced by the number of links of the published content.
Furthermore, the patent discusses a creditability factor for authors. For this, verified information about the profession or the role of the author in a company is relevant. The relevance of the profession to the topics of the published content is also decisive for the credibility of the author. The level of education and training of the author can also have a bearing here.
The verified information about the author can include the number of other publications of the author that are relevant to the author’s online content item. The verified information about the author can include the number of citations to the author’s online content item that are made in other publications of one or more different authors. The verified information about the author can include information about awards and recognition of the author in one or more fields. The credibility factor can be further based on the relevancy of the one or more fields to the author’s online content item. The verified information about the author can include feedback received about the author or the author’s online content item from one or more organizations. The credibility factor can be further based on the relevancy of the one or more organizations to the author’s online content item and the feedback received. The verified information about the author can include revenue information about the author’s online content item.
Other factors mentioned are:
- Experience of the author due to time: The longer an author has already published on a topic, the more credible he is. Google can algorithmically determine the experience of the author/publisher via the date of the first publication in a topic field.
- Number of content published on a topic: If an author publishes many articles on a topic, it can be assumed that he is an expert and has a certain credibility. If the author is known to Google as an entity, it is possible to record all content published by him in an entity index such as the Knowledge Graph or Knowledge Vault and assign it to a topic field. This can be used to determine the number of contents per topic field.
- Time elapsed until last publication: The longer it has been since an author’s last publication on a topic field, the more a possible reputation score for this topic field decreases. The more recent the content, the higher the score.
- Mentions of the author / publisher in award and best-of lists: If the author has received awards or other forms of public recognition in the topic area of the online content item or for the online content item itself, the author’s credibility factor can be positively influenced.
If the author’s online content item is published by a publisher that regularly publishes works of authors who have received awards or other public recognition, thereby increasing the credibility of the publisher itself, the author’s credibility score can be influenced.
Furthermore, mentions in best-seller lists can have an influence on the credibility measurement.
The level of success of the author, either in relation to a particular online content item, or generally, can be measured to some degree by the success of the author’s published works, for example, whether one or more have reached best seller lists or by revenue generated from one or more publications. If this information is available and indicated relative success of the author in a particular field, this can positively influence the author’s credibility factor.
- Name recognition of the author/publisher: The higher the level of awareness of an author/publisher, the more credible he is and the higher his authority in a subject area. Google can algorithmically measure the level of awareness via the number of mentions and the search volume for the name. In addition to the patent already mentioned, there are further statements from Google on the degree of awareness as a possible ranking factor.
Implications for SEO
- Increased Importance of Authorship: The credibility and reputation of content authors become crucial ranking factors. SEO strategies must now consider the author’s authority on the subject matter, their online presence, and their reputation across platforms.
- High-Quality Content: The emphasis on author credibility underscores the importance of high-quality, well-researched content. Content that is authoritative, accurate, and provides value to the reader will likely rank higher.
- Beyond Keywords and Backlinks: While traditional SEO factors like keywords, backlinks, and user engagement metrics remain important, the author’s reputation and credibility factor into the content’s ranking. SEO strategies must adapt to include authorship as a key component.
- Engagement as a Credibility Indicator: User engagement with content, such as comments, shares, and reviews, may influence the author’s reputation score.
- Structured Data Markup: Implementing structured data to highlight authorship information, such as using Schema.org markup for authors, can help search engines understand and attribute credibility to the content creators.
- Building a Cross-Platform Presence: Authors should aim to build their reputation across multiple platforms, including social media, industry forums, and other publication sites. A strong, consistent presence can enhance their overall credibility and the SEO performance of their content.
Sentiment detection as a ranking signal for reviewable entities
The Google patent Sentiment detection as a ranking signal for reviewable entities describes how sentiment analysis can be used to identify sentiments around reviewable entities in documents. The results can then be used for ranking entities and related documents.
Evaluable entities include people, places, or things about which sentiment can be expressed, such as restaurants, hotels, consumer products such as electronics, movies, books, and live performances.
Structured unstructured data can be used as a source. Structured reviews are collected from popular review websites such as Google Maps, TripAdvisor, Citysearch, or Yelp.
The entities stored in the Sentiment database are represented by tuples in the form of the entity ID, entity type and one or more reviews. The reviews are assigned different scores, which are calculated in the Ranking Analysis Engine.
In the Ranking Analysis Engine, sentiment scores concerning the respective reviews including additional information such as the author are determined.

This patent also discusses the use of interaction signals to complement sentiment in terms of ranking as a factor.
- User Interaction Score
- Consensus Sentiment Score
To determine a user interaction score, user signals such as SERP CTR and duration of stay are addressed.

Systems and Methods for Re-Ranking ranked Search Results
The patent US20190188207A1 is published for the United States and WIPO. The last publication date of the application is June 20, 2019, and it was granted as US10503740B2 on December 10, 2019. The anticipated expiration date of the patent is May 17, 2033. The inventors listed for this patent are Chung Tin Kwok, Lei Zhong, and Zhihuan Qiu. The current assignee is Google LLC.
When a user submits a search query, the search engine identifies and ranks search results based on various factors, including the relevance of the search results to the query. However, this process can lead to situations where search results with similar or substantially identical content are ranked differently. This discrepancy often arises because some entities known to the search engine do not produce original content; instead, they redistribute content authored by others. Conversely, other entities are recognized for producing original content.
The patent highlights a specific issue where documents associated with entities not known for original authorship might receive higher relevancy scores and, consequently, higher rankings in search results. This situation is problematic because it can prioritize content from entities that merely redistribute others’ original work over content from entities that are the original authors. The background sets the stage for the invention by underscoring the need for a method to re-rank search results in a way that better reflects the originality of the content and the authorship behind it, aiming to improve the quality and relevance of search results presented to users.
Claims
- Re-ranking Methodology: Claims detail a computer-implemented method for re-ranking search results where documents satisfying a search query are initially ranked. If two documents are similar and the entity associated with the lower-ranked document meets a predefined authorship criterion indicating higher originality or authorship quality, the rankings of these documents are swapped.
- System Configuration: Claims describe a system equipped with at least one processor and memory storing programs for executing the re-ranking process. This system is capable of obtaining ranked search results, evaluating document similarity, assessing authorship quality, and adjusting search result rankings accordingly.
- Computer-Readable Medium: Claims include a computer-readable medium storing programs that, when executed by a processor, perform the method of re-ranking search results based on similarity and authorship criteria.
- Priority and Indexing Requests: Some claims focus on issuing high priority requests for crawling and indexing content deemed as original or of high authorship quality, ensuring such content is promptly added to the search engine’s index.
- Content Evaluation: Claims detail methods for evaluating whether content is new relative to known content in the index, including techniques for comparing content shingles (sets of tokens) to determine content uniqueness and originality.
- Authorship Determination: Several claims outline methods for determining whether an entity is an author of original content, based on evaluating submitted content against known content and identifying unique or first-instance content contributions.
- Registration and Verification of Authors: Claims also cover the process of registering entities as authors of content, including verifying authorship through various mechanisms and updating the search engine’s index to reflect verified authorship status.
The patent describes how search engines can take into account not only the references to the author’s content, but also the portion he or she has contributed to a thematic document corpus in an author score.
The patent presents a system, a computer-readable storage medium storing at least one program, and a computer-implemented method for re-ranking search results that have already been ranked in response to a search query. The essence of the patent is to adjust the ranking of search results based on the authorship and originality of the content, rather than solely on traditional relevance metrics.
“In some embodiments, determining the original author score for the respective entity includes: identifying a plurality of portions of content in the index of known content identified as being associated with the respective entity, each portion in the plurality of portions representing a predetermined amount of data in the index of known content; and calculating a percentage of the plurality of the portions that are first instances of the portions of content in the index of known content.”
This Google patent was drawn in August 2018. It describes the refinement of search results according to an author scoring including a citation scoring. Citation scoring is based on the number of references to an author’s documents. Another criterion for author scoring is the proportion of content that an author has contributed to a corpus of documents.
wherein determining the author score for a respective entity includes: determining a citation score for the respective entity, wherein the citation score corresponds to a frequency at which content associated with the respective entity is cited; determining an original author score for the respective entity, wherein the original author score corresponds to a percentage of content associated with the respective entity that is a first instance of the content in an index of known content; and combining the citation score and the original author score using a predetermined function to produce the author score;
Implications for SEO
- Emphasis on Original Content: The patent underscores the importance of creating and publishing original content. Websites and content creators who produce unique, high-quality content are likely to benefit from improved search rankings as search engines prioritize originality and authorship quality. This shifts the focus towards the value of content uniqueness over merely optimizing for keywords or backlinks.
- Authorship as a Ranking Factor: The concept of authorship quality and its impact on content ranking suggests that search engines may consider the reputation and credibility of content creators as part of their ranking algorithms. This could lead to the development of strategies aimed at establishing and highlighting the expertise and authority of authors in their respective fields.
- Content Syndication and Redistribution: For websites that rely on syndicating or redistributing content from other sources, this patent indicates a potential need to reassess their strategies. While syndicated content can still be valuable, search engines might prioritize content from the original source, affecting the visibility of syndicated versions.
- SEO Strategies for Publishers: Publishers and content creators might need to adopt new SEO strategies that focus on proving the originality and authorship quality of their content. This could involve leveraging metadata, structured data, or other means to signal to search engines the original source of content and the credibility of the authors.
- Impact on Content Marketing: Content marketing strategies may need to evolve to place even greater emphasis on the creation of original, high-quality content that provides real value to users. Brands and marketers might invest more in thought leadership and original research to stand out in search results.
- Monitoring and Protecting Content: There could be an increased need for tools and strategies to monitor the web for duplicate content and to protect original content from being copied without attribution. Content creators may need to be more vigilant in asserting their rights and ensuring their content is correctly indexed as the original source.
Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources
The scientific paper Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources from Google deals with the algorithmic determination of the credibility of websites.
This scientific paper deals with how to determine the trustworthiness of online sources. In addition to the analysis of links, a new method is presented that is based on the verification of published information for accuracy.
We propose a new approach that relies on endogenous signals, namely, the correctness of factual information provided by the source. A source that has few false facts is considered to be trustworthy.
For this, methods of data mining are used, which I have already discussed in detail in the articles How can Google identify and interpret entities from unstructured content? and Natural language processing to build a semantic database.
We call the trustworthiness score we computed Knowledge-Based Trust (KBT). On synthetic data, we show that our method can reliably compute the true trustworthiness levels of the sources.
The previous method of assessing the trustworthiness of sources based on links and browser data on website usage behavior has weaknesses, as less popular sources are given a lower score and are unfairly shortchanged, even though they provide very good information.
Using this approach, sources can be rated with a “trustworthiness score” without including the popularity factor. Websites that frequently provide incorrect information are devalued. Websites that publish information in line with the general consensus are rewarded. This also reduces the likelihood that websites that attract attention through fake news will gain visibility on Google.
Website Representation Vector
The Google patent “Website Representation Vectors” used to classify websites based on expertise and authority.
Here’s a summary of the key points from the patent:
- The patent application was filed in August 2018, and it covers a range of industries, including health and artificial intelligence sites as examples.
- The patent application uses Neural Networks to understand patterns and features behind websites to classify those sites. This classification is based on different levels of expertise, with examples given such as doctors (experts), medical students (apprentices), and laypeople (nonexperts) in the health domain.
- The patent application does not specifically define a “quality score”, but it mentions classifying websites based on whether they meet thresholds related to these scores. These scores could potentially relate to a range of quality measures of sites relative to other sites.
- The patent also discusses how search queries from specific knowledge domains (covering specific topics) might return results using classified sites from the same knowledge domain. It aims to limit possible results pages based on classifications involving industry and expertise that meet sufficient quality thresholds.
Google could use these Website Representation Vectors to classify sites based on features found on those sites. The classifications can be more diverse than representing categories of websites within knowledge domains, breaking the categories down much further.

This patent deals with the generation of author vectors using neural networks. Specifically, the patent describes obtaining a set of sequences of words, where these sequences are classified as being authored by a specific author. These sequences include a plurality of first sequences of words, and for each first sequence, a respective second sequence of words that follows the first sequence. The neural network system is trained on these first and second sequences of words to determine an author vector that characterizes the author.

Once an author vector has been computed, it can be used to determine the cluster to which a user’s author vector belongs. The response generated by an automatic response system can then be conditioned on the representative author vector for that cluster.
The last two mentioned patents could be used by Google classifying and evaluate source entities like authors or companies and domains in topical areas. This could be used by vector space analyses and embeddings. More on this topic in my post How can Google identify and rank relevant documents via entities, NLP & vector space analysis?

How Google fights Disinformation
In this whitepaper Google introduces 2019 on the security conference in munich there are many interesting references to the E-E-A-T concept. I summarized the whitepaper in my post “Insights from the Whitepaper “How Google fights misinformation” on E-A-T and Ranking”
Search Quality Evaluator Guidelines
The Search quality evaluatior guidelines are published for the thousands of quality rater worldwide, that are rating the quality of search results. The feedback has an impact on the development of the ranking algorithms. In the guidelines Google introduced E-A-T for the very first time and you can find detailed informations how quality rater should rate in terms of E-E-A-T. So it is the most important ressource to gain knowledge around E-E-A-T.
Google documentation on Panda
There is no officially communicated relation between Panda now Coati and E-E-A-T, but the relationship is obvious. You can find several hints in Google statements, that Coati (ex Panda) is also part of E-E-A-T. So you have to check Googles information around quality of content and Coati.

Google emphasizes the importance of high-quality websites in search results and provides guidance on what constitutes a high-quality site.
Summary of the documentation:
- Google has been focused on improving the visibility of high-quality websites in its search results.
- The “Panda” algorithm change has positively affected the rankings of many high-quality websites.
- Publishers are advised to prioritize delivering an excellent user experience rather than obsessing over Google’s ranking algorithms.
- Google has made over a dozen ranking algorithm tweaks since the launch of Panda.
- The definition of a high-quality site includes factors like trustworthiness, expertise, original content, value, and user-friendliness.
- Google does not disclose its ranking signals to prevent manipulation of search results.
- Webmasters are encouraged to concentrate on creating high-quality content and not optimizing for specific Google algorithms.
- Low-quality content on a website can impact the rankings of the entire site, so it’s advised to improve or remove such content.
- Google is continuously working on algorithmic iterations to support high-quality websites in getting more traffic from search.
- Webmasters are encouraged to ask themselves the same questions Google uses when evaluating the overall quality of their sites..
-
Would you trust the information presented in this article?
-
Is this article written by an expert or enthusiast who knows the topic well, or is it more shallow in nature?
-
Does the site have duplicate, overlapping, or redundant articles on the same or similar topics with slightly different keyword variations?
-
Would you be comfortable giving your credit card information to this site?
-
Does this article have spelling, stylistic, or factual errors?
-
Are the topics driven by genuine interests of readers of the site, or does the site generate content by attempting to guess what might rank well in search engines?
-
Does the article provide original content or information, original reporting, original research, or original analysis?
-
Does the page provide substantial value when compared to other pages in search results?
-
How much quality control is done on content?
-
Does the article describe both sides of a story?
-
Is the site a recognized authority on its topic?
-
Is the content mass-produced by or outsourced to a large number of creators, or spread across a large network of sites, so that individual pages or sites don’t get as much attention or care?
-
Was the article edited well, or does it appear sloppy or hastily produced?
-
For a health related query, would you trust information from this site?
-
Would you recognize this site as an authoritative source when mentioned by name?
-
Does this article provide a complete or comprehensive description of the topic?
-
Does this article contain insightful analysis or interesting information that is beyond obvious?
-
Is this the sort of page you’d want to bookmark, share with a friend, or recommend?
-
Does this article have an excessive amount of ads that distract from or interfere with the main content?
-
Would you expect to see this article in a printed magazine, encyclopedia or book?
-
Are the articles short, unsubstantial, or otherwise lacking in helpful specifics?
-
Are the pages produced with great care and attention to detail vs. less attention to detail?
-
Would users complain when they see pages from this site?
Google on Creating helpful, reliable, people-first content
Google’s ranking systems prioritize content that is helpful and reliable for people, rather than solely focusing on search engine rankings.
Summary og Googles documentation:
- Google’s automated ranking systems aim to present helpful and reliable information primarily for people’s benefit, not just for search engine rankings.
- Creators can self-assess their content to determine if it meets the criteria for being helpful and reliable.
- Content and quality questions to consider when evaluating content include originality, completeness, insightfulness, and value compared to other search results.
- Expertise questions involve assessing trustworthiness, authoritativeness, and the depth of knowledge in the content.
- Providing a great page experience is important, and it involves various aspects beyond just one or two elements.
- A focus on people-first content means creating content primarily for human users rather than trying to manipulate search engine rankings.
- Avoiding search engine-first content and concentrating on people-first content is recommended for success with Google Search.
- Google’s SEO guide covers best practices for SEO, but it should be applied to people-first content.
- Understanding E-E-A-T (Expertise, Authoritativeness, Trustworthiness) is crucial, with trust being the most important aspect. Content should align with strong E-E-A-T for certain topics.
- Search quality raters provide insights into the quality of search results but do not directly influence rankings.
- Evaluating content in terms of “Who, How, and Why” helps creators stay aligned with Google’s ranking goals.
- Indicating who created the content, how it was produced, and why it was created are essential considerations for content creators.
- Content should be created primarily to help people, not just to attract search engine visits or manipulate rankings through automation.
Overall, the key message is to prioritize creating helpful and reliable content that serves people’s needs and aligns with Google’s ranking principles.
Google has developed a system called “topic authority” to help determine the expertise of publications in specific topic areas, such as health, politics, or finance, in order to better surface relevant and expert content in Google Search and News.
Summary of the documentation:
- Major news events are often covered by numerous news sites, making it challenging for users to find expert sources for specific topics.
- Google has introduced a system called “topic authority” to identify expert sources in specialized topic areas.
- How topic authority works:
– It evaluates signals like the notability of a source for a specific topic or location.
– It considers influence and original reporting, looking at how often a publication’s original reporting is cited by other publishers.
– It assesses a source’s reputation, including their history of high-quality reporting and recommendations from expert sources.
- Topic authority helps with news searches by surfacing local and regional content from trusted publications for relevant queries.
- For instance, during a flood in a particular region, topic authority helps identify and prioritize content from local publications that cover topics in that area.
- The emphasis on topic authority means that original reporting from news teams familiar with a location and topic is more likely to be showcased.
- Publishers can improve their topic authority by providing excellent coverage in areas they specialize in, aligning with the system’s criteria and Google’s guidance on creating helpful content.
The topic authority system looks at a variety of signals to understand the degree of expertise a publication has in particular areas. A few of the most prominent signals are:
-
How notable a source is for a topic or location: Our systems understand publications that seem especially relevant to topics or locations. For example, they can tell that people looking for news on Nashville high school football often turn to a publication like The Tennessean for local coverage.
-
Influence and original reporting: Our system looks at how original reporting (for example the publisher that first broke a story) is cited by other publishers to understand how a publication is influential and authoritative on a topic. In 2022, we added the Highly Cited label to give people an easier way to identify stories that have been frequently cited by other news organizations.
-
Source reputation: Our system also looks at a source’s history of high-quality reporting, or recommendations from expert sources, such as professional societies. For example, a publication’s history doing original reporting or their journalistic awards are strong evidence of positive reputation for news websites.
- The dimensions of the Google ranking - 25. April 2024
- Interesting Google patents for search and SEO in 2024 - 3. April 2024
- What is the Google Shopping Graph and how does it work? - 27. February 2024
- “Google doesn’t like AI content!” Myth or truth? - 19. February 2024
- Most interesting Google Patents for semantic search - 12. February 2024
- How does Google search (ranking) may be working today - 4. February 2024
- Success factors for user centricity in companies - 28. January 2024
- Social media has become one of the most important gatekeepers for content - 28. January 2024
- E-E-A-T: Google ressources, patents and scientific papers - 24. January 2024
- Patents and research papers for deep learning & ranking by Marc Najork - 21. January 2024