What is the Google Knowledge Vault?
The Google Knowledge Vault was a project by Google that aimed to create an extensive knowledge database that automatically extracts information from the internet and puts it into a structured form. It was seen as a successor to Google Knowledge Graph, which has a similar function but is mainly based on manually curated data sources.
The truth is that Google hasn’t mentioned the Knowledge Vault since 2015.
We don’t know whether the KV ever was or is still part of the Google infrastructure.
But the original approach and objective that the Knowledge Vault had is up to date.
Namely the extraction and understanding of unstructured data for mining long-tail knowledge.
The big challenge when compiling a knowledge database algorithmically is to give equal consideration to the factors of completeness and accuracy. The main task of the Knowledge Vault is data mining about entities, including Lontail entities that are not recorded in the Knowledge Graph.

Knowledge Vault was intended to automatically collect facts and assess the trustworthiness of this information through machine learning and understanding text from the web. The goal was to have a broader base of information that could be used for various Google services, such as improving search results or providing information for Google Assistant.
The system should be able to classify facts as true or false with a certain probability, based on the reliability of the sources and the consistency of the information from different sources. However, it is important to note that Google is regularly working on various research and development projects and the exact details and current status of Knowledge Vault are not known without up-to-date information from Google itself.
Contents
What we know about the Knowledge Vault?
The Knowledge Vault was introduced by Google in 2013 and has been a mystery ever since. There has been little further information since then. That’s why I would like to gather all the official information here and contribute my own thoughts.
Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion
The concept and idea of the Knowledge Vault is based on the paper “Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion”.
The document outlines the creation of the Knowledge Vault (KV), a web-scale probabilistic knowledge base. The authors, Xin Luna Dong et al., address the limitations of existing large-scale knowledge bases like Wikipedia, Freebase, YAGO, Microsoft’s Satori, and Google’s Knowledge Graph. These knowledge bases, despite their size, are far from complete and suffer from a lack of information about many entities and relationships.
The Knowledge Vault aims to scale up knowledge base construction by automating the extraction of facts from the web, using a variety of sources such as text, tabular data, page structure, and human annotations. It leverages supervised machine learning methods to fuse these different sources of information. The KV is significantly larger than any previously published structured knowledge repository, containing 1.6 billion triples of which 324 million have a confidence of 0.7 or higher, and 271 million have a confidence of 0.9 or higher. This represents about 38 times more confident facts than the largest comparable system at the time.
The paper discusses the challenges in building the KV, such as modeling mutual exclusions between facts and representing a vast variety of knowledge types. It also touches on the potential for further improvement, like extending the schema to capture more web-mentioned relations and handling the long tail of concepts difficult to capture in any fixed ontology. The authors provide a detailed comparison of the quality and utility of different information sources and extraction methods, and suggest that future work may involve crowdsourcing techniques to acquire common sense knowledge not available on the web.
The Knowledge Vault differentiates itself by combining noisy extractions with prior knowledge derived from existing knowledge bases, and by being a structured repository of knowledge that is language-independent. It utilizes a probabilistic inference system to compute calibrated probabilities of fact correctness. The work presented in this paper contributes to the field by offering a scalable approach to knowledge base construction that can significantly expand the breadth of human knowledge available for various applications.
Knowledge Vault and Knowlege-Based Trust
A very interesting presentation from XIN Luna Don at the Stanford University in 2015 about Knowledge Based Trust also mentioned the Knowledge Vault. The presentation based on the paper called “Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources” by XIN Lunda Don and colleagues.
The paper presents a novel approach to evaluating the quality of web sources. Instead of relying on external signals like hyperlinks and browsing history, the authors propose a method that depends on the correctness of factual information provided by a source, termed as Knowledge-Based Trust (KBT).
KBT assesses trustworthiness by extracting facts from web sources using information extraction techniques typically used to construct knowledge bases like Google’s Knowledge Vault (KV). KV extracts structured information from the web to build a massive database of facts by using 16 different extraction systems. These extracted facts are triples (subject, predicate, object) and are automatically processed to form a knowledge base. The authors acknowledge that errors during extraction are more prevalent than factual errors on web pages, and these must be distinguished to assess a source’s trustworthiness accurately.
The paper introduces a multi-layer probabilistic model that differentiates between factual errors in the source and errors in the extraction process. This distinction is vital for reliably computing the trustworthiness of web sources. The authors present an efficient, scalable algorithm for performing inference and parameter estimation within this probabilistic model.
The model’s effectiveness is demonstrated through its application to a large dataset, comprising 2.8 billion extracted triples from the web, which allowed the estimation of the trustworthiness of 119 million webpages. The paper’s contributions are summarized as follows:
A sophisticated probabilistic model to distinguish between factual and extraction errors.
An adaptive method to decide the granularity of sources to improve computational efficiency.
A large-scale evaluation showing the model’s efficacy in predicting the trustworthiness of webpages.
The authors also discuss the potential of the KBT score as an additional signal for search engines to evaluate website quality and improve search results. They suggest that this approach can be extended beyond knowledge extraction to other tasks involving data integration and data cleaning.
Overall, the paper provides an innovative solution to the challenge of automatically determining the reliability of web sources based on the factual correctness of their content, leveraging the vast amount of information available on the web and the redundancy within it to produce a trustworthiness score.
Knowledge Based Trust could be a also a signal in context of E-E-A-T as I mentioned in my articles E-E-A-T: More than an introduction to Experience ,Expertise, Authority, Trust and The most interesting Google patents and scientific papers on E-E-A-T.
The todays Knowledge Vault as an Entity Extraction and validation process
To date, the official name of Google’s semantic database is Knowledge Graph. The term Knowledge Vault was no longer mentioned by Google after 2015. When the Knowledge Vault was first introduced by Google in 2013 it should be the central Knowledge Base including data form the Knowledge Graph and the open web.

The original perspective for the Knowledge Vault was to replace the Knowledge Graph, but this has not yet happened.
In my opinion, the Knowledge Vault today has more the function of an upstream knowledge repository. Non-validated extracted entities are recorded there and enriched with information about the entities.
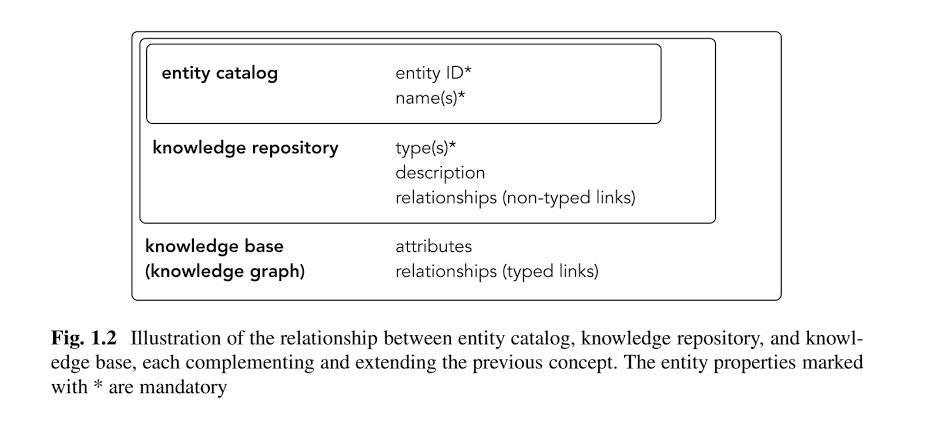
The validity of the entities, attributes and other information is checked for correctness via frequencies. As soon as a threshold value is reached, the entities are transferred to the Knowledge Graph and displayed in the SERPs with their own Knowledge Panel.
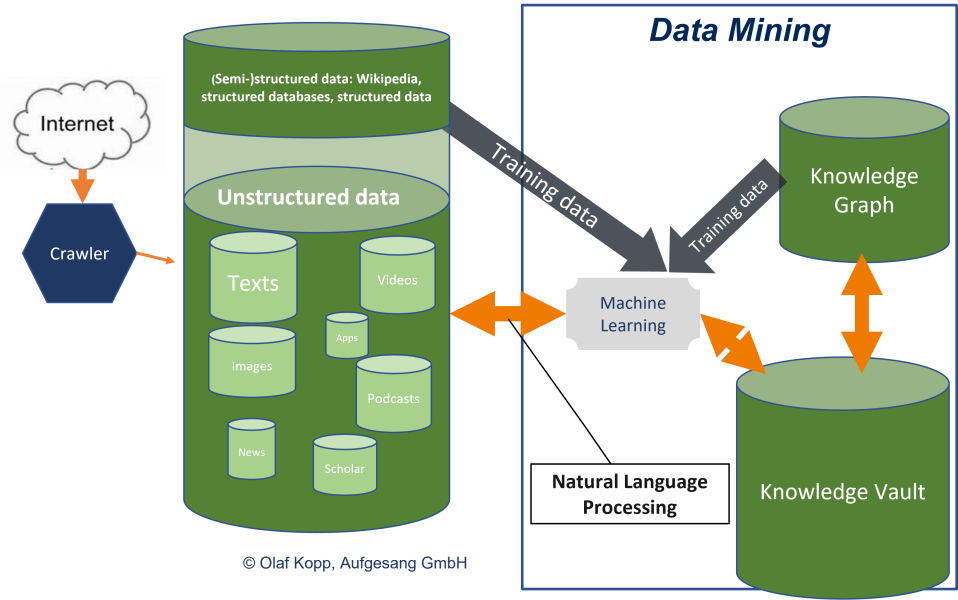
The Knowledge Vault is also responsible as a function module for Named Entity Extraction, Data Mining via Natural Language Processing and Validation.
More about this in my articles Natural language processing to build a semantic database , All you should know as an SEO about entity types, classes & attributes, Unwrapping the Secrets of SEO: The Role of Machine Learning in Google Search.
Misconceptions about the Knowledge Vault
Here are some misconceptions you can read about the Google Knowledge Vau4lt:
The Knowledge Vault is an algorithm
It is highly unlikely that the Knowledge Vault is a single algorithm of its own. The Knowledge Vault describes a process for mining knowledge. Technologically, such a process can be carried out using natural language processing. Natural language processing belongs to the field of machine learning and consists not only of an algorithm, but is a multi-stage process that leads through several levels. It is therefore not correct to speak of the Knowledge Vault as an algorithm.
The Knowledge Vault is the same as the Knowledge Graph
The Knowledge Graph is a semantic database primarily based on information from structured and semi-structured data sources. (You can read more about this in my blog). The Knowledge Vault is primarily designed to extract information from unstructured data sources. (You can read more about this in my blog). The Knowledge Graph and Knowledge Vault are therefore related to each other, but are two different things.
- The dimensions of the Google ranking - 25. April 2024
- Interesting Google patents for search and SEO in 2024 - 3. April 2024
- What is the Google Shopping Graph and how does it work? - 27. February 2024
- “Google doesn’t like AI content!” Myth or truth? - 19. February 2024
- Most interesting Google Patents for semantic search - 12. February 2024
- How does Google search (ranking) may be working today - 4. February 2024
- Success factors for user centricity in companies - 28. January 2024
- Social media has become one of the most important gatekeepers for content - 28. January 2024
- E-E-A-T: Google ressources, patents and scientific papers - 24. January 2024
- Patents and research papers for deep learning & ranking by Marc Najork - 21. January 2024